博文
计算社会经济学——一门正在形成的交叉研究方向
|
很多科学分支都经历过方法论从定性到定量的范式转移。即便是以“理论模型-定量预测-实验验证”为方法论闭环的,现在看起来最能代表定量科学成就的物理学,在其发展的早期也经历了以定性解释为主的时期。举个例子,两千多年前,亚里士多德就提出了一个著名的定性理论——四元素论(The Four Elements Theory),认为土(earth)、水(water)、气(air)、火(fire)这四种基本的元素构成了物理世界的物质基础(the material basis of the physical world)。在几乎差不多的时期(先秦),中国古代哲学家也提出了类似的五元素理论(五行说),认为金(metal)、木(wood)、水(water)、火(fire)、土(earth)五种元素按照不同比例混合即可以构成世界上所有的物体。亚里士多德的物理理论在两千年左右的时间内代表了人类对物理世界主流的理解,很可能是人类历史上影响时间最长、范围最广的理论之一。直到近代科学出现,归功于大量化学和物理实验以及对应的定量分析手段,他的四元素理论和动力学理论才分别被原子论(Atomic Theory)和牛顿定律(Newton’s Law)替代。
与研究物质和运动的物理科学对应,社会科学研究的是以人的活动和关系为基础的社会结构,它包括了社会学、经济学、法学、语言学、政治学等等多个学科。与物理科学相比,从定性到定量这条道路对于社会科学而言,要困难得多。首先,社会科学研究的对象要比物理科学复杂得多。人是社会科学研究最重要的基本单位之一,其地位类似于物理科学中的原子[1]。然而,人的行为具有异质性和阵发性[2]:不同的人之间行为差异很大,而即便同一个人在不同时空下行为差异也很大。因此,除了在分析拥挤的人流等极少量的场景中获得了一定成功[3,4],把人群简化成一堆同质化的原子只会消除大量有趣的社会现象。还有一些社会科学分析的对象,例如政策和法律条文,不仅复杂,而且天然地不容易用数值的手段来刻画。其次,社会科学的研究对象具有极大的不完备性和不确定性。影响社会发展的因素数不胜数,任何包罗万象的理论都不可能将它们全盘纳入,而单个因素也是不独立不稳定的,受到外部环境和其他因素的影响。这就使得在一个封闭的环境中,通过可控的重复实验对社会理论进行定量化验证变得不可能——而这恰恰是物理科学和其他自然科学得以螺旋前进的基石[5]。与此同时,社会科学也缺乏预测未来的能力——很多时候专家和理论模型得到的预测并不优于随机乱猜[6]。但这些错误预测也无法杀死理论,因为错误可以被归因于未知的因素和突发的事件,而不是理论本身的缺陷。
就目前来看,社会科学在发展其定量化方法的过程中,仅仅是形成了某种“事后诸葛”般的明智。一些经过修修补补的理论模型,总是可以对已经发生的事情给出定性正确甚至定量精确的解释,但是对于未来,却无能为力。面对这种困境,研究人员不能开倒车,退回到定性描述,而是要坚持用定量化的方法给出解释和预测,并把解释能力和预测精度作为评价理论适用性的指标。事实上,最近社会科学方面的研究定量化程度越来越高,也越来越依赖于真实数据[7,8]。但是,传统的获取数据的方法存在很多局限性。例如,通过问卷得到的数据往往样本规模很小,而且数据可能存在系统误差,因为被试在回答问卷的时候往往倾向于给出更易被社会接受的答案,而非真实的答案[9]。更准确且更大规模的数据,例如经济普查数据,又往往要消耗大量的资源才能获得,并且时效性很差。在很多贫困的地区,这种全国性的普查甚至是不现实的。对于社会科学的研究人员而言,一个以前从未出现过的重要机会就是全世界都在经历的数据化浪潮[10]。经济社会发展的过程数据,人类活动的行为数据,被越来越多的数据采集终端和传感设备记录下来。然而,这些数据往往不是传统社会科学惯常处理的数据,而是卫星遥感、移动通讯、社交媒体等等新型数据。一方面,理解和分析这类数据,需要前沿的数据挖掘和机器学习方法,这对以统计分析为主要工具的传统社会科学研究者提出了挑战。另一方面,这些数据规模更大、实时性更强、精度更高,既可以降低小样本数据的稀疏性和偏差度,又可以减少过程中的不可见部分(例如经济普查数据就是典型的非实时数据,两个数据点之间往往跨越几年时间,中间的过程全然不可见),因此从原理上讲可以更好地感知社会经济态势,评价和修正原有理论,启发和孕育新理论,发现可能的异常,预测未来的趋势等等。尽管这依然不能一劳永逸地将社会科学转化为完全定量化的学科,甚至达到自然科学的水平(我们也不应有此奢望),但毫无疑问能够将社会科学的“科学性”往前推动一大步。
以上的这些挑战和尝试,导致了一门新学科的涌现,它基于大规模的真实数据,用定量化的手段研究社会经济发展中的各种现象,特别是与社会过程有关的经济发展问题,以及与经济发展有关的社会问题。我们不妨称其为计算社会经济学(Computational Socioeconomics),它是社会科学中一个新兴的,极小的但又充满活力和指向未来的分支。它既可以被看作社会经济学因为方法论的变革所形成的新分支,也可以被看作计算社会科学因为研究对象的聚焦所形成的新分支。在上面的定义中,有几个关键词是特别需要注意的。第一是“定量化”,强调用数值而非描述来刻画问题和呈现结果。从定性到定量是科学研究质的飞跃。公元前5世纪,古希腊医生希波克拉底(Hippocrates)认为人体内有4种体液(即血液、粘液、黄胆汁、黑胆汁),每种体液所占比例的不同决定了人的气质差异,而人的气质类型也可以分为四类,分别是多血质、胆汁质、黏液质和抑郁质。这一定性的理论,如同亚里士多德的四元素论对物理学的影响一样,统治了心理和人格分析领域两千多年。遗憾的是,这种包含了一定合理成分但纯粹定性描述的理论,没有在发展过程中累积科学上坚实的成果。直到心理学家利用标准化量表获得对于大五人格的量化评价后,人格分析才成为一个重要的研究分支,并在很多社会心理学的问题中发挥中心性的作用[11]。第二是“真实数据”,强调理论模型必须要服从真实数据,以对真实数据的解释和预测能力为评价准绳。经济学是一门高度量化的科学,几乎所有理论模型背后都有一套对应的优美的方程,如果给定那些参数的值,很多目标变量原则上是可以计算的。然而,大部分经济学的研究只停留在这种虚幻的量化中,没有和真实数据结合起来。这就导致了经典的经济学理论陷入了优美程度大于实用程度,理想化超过了现实化的窘境。短期而言,它对于扑面而来的经济危机无法给出正确的预判[12](但是在危机过后总能找到理论上优美且合理的解释[13]);长期而言,它对于全世界位于发展中的百来个国家地区给不出行之有效的经济发展建议[14]。第三是“大规模”,强调尽可能获取能够直接反映全体的数据样本(全体尺度数据,population-scale data)。数据样本规模小,有时候带来的不仅仅是偏差,还可能是完全错误的结论。例如,一个在较小规模网络中被多次验证且为学术界广泛接受的理论,是社会互动的强度(可以用电话通信的频率和时长,以及社交媒体上评论、回复和提及的次数等指标来衡量)随着连边的长度范围(可以用去掉该连边后两个个体的网络最短距离衡量——这个长度范围如果很大,就说明连边的两个个体处于社交网络中距离很远、重叠很少的两个不同社区)持续衰减[15,16],但最近通过对11组全体人口尺度社交网络数据的分析显示[17],长程社交连边的社会互动强度并不弱于短程连边,从而从根本上挑战了我们对社交网络组织结构的理解。
待分析数据多样性和规模的增加,会给这个新兴科学分支在方法论上带来两个改变。一是为了分析遥感图像、街景照片、社交网络、文本内容这类数据,简单的统计分析工具无法满足需求,必须高度依赖于人工智能的技术,特别是数据挖掘和机器学习的先进技术,例如深度学习算法[18]。二是我们会接触到很多全体尺度的数据,这时候抽样不再是用于估计全体性质的一种必要的方法,而是我们通过对少量抽样样本进行更多维度的数据补充甚至人工标注后,再把这些数据用作机器学习的训练数据,建立从原数据维度推断出新增数据维度的模型,最终能够推断出全体尺度上的新增维度。这是一种可以和传统抽样方法和问卷调查在方法论上具有承接关系,但是威力强得多的方法。举个例子,我们比较容易得到一个国家全体人口尺度基于移动手机的通讯和空间移动记录,但是获得每个家庭收入的情况却非常困难,一是很多较贫困地区根本就不做全民经济普查,二是这类数据往往因为是国家机密而不轻易向科研机构开放。这种情况下,我们可以通过相对较小的成本,利用传统的抽样、问卷等方式,获得一部分家庭的收入情况,再利用机器学习方法建立通过移动手机数据预测家庭收入的模型,从而推断出所有有移动手机数据的人口的家庭收入[19]。尽管这个数据不是完全准确的,但是往往精度很高,而且是用很小的成本获得了几乎所有人的高价值数据。如图1 所示,这种结合全体尺度易获得数据,少量难以获得的高价值数据和机器学习算法,去推断全体尺度难以获得的高价值数据,是计算社会经济学研究中很有代表性的一种新方法,体现了社会科学和计算机科学理念和方法的深度融合。
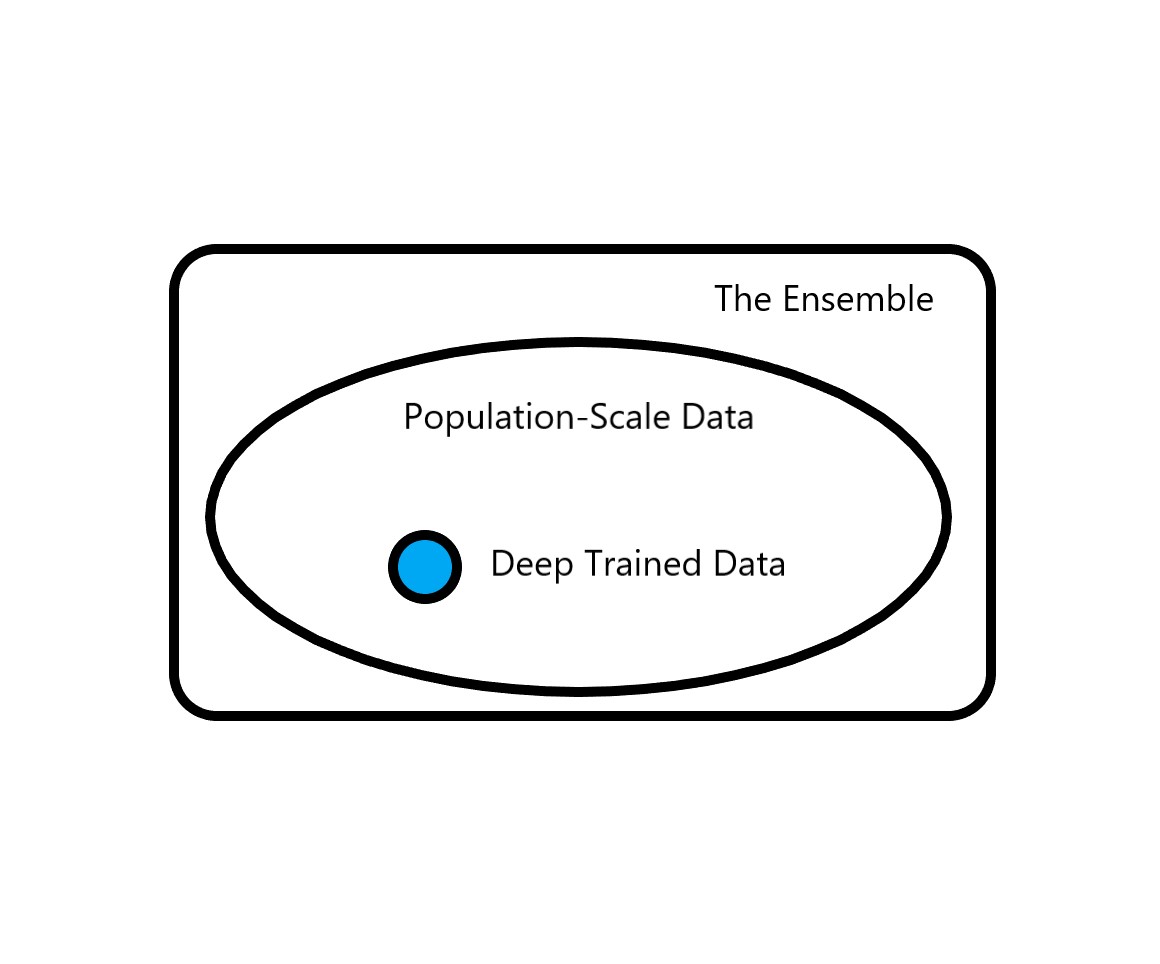
图1:全体样本、易获得全体尺度数据和少量高价值数据样本的关系示意图。其中Deep Trained Data所包含的数据维度往往要多于Population-Scale Data。
长期而言,不管计算社会经济学会成为一个有独立边界的新科学分支,还是会完全融入到社会科学中去,上面讨论的这种由大数据和人工智能发展所驱动的新理念和新方法论,毫无疑问会成为未来社会科学主流的方法论,并且将不可逆转而深刻地改变整个社会科学。
参考文献:
[1] P. Ball, Critical mass: How one thing leads to another (Macmillan, 2004).
[2] A.-L. Barabasi, Bursts: the hidden patterns behind everything we do, from your e-mail to bloody crusades (Penguin, 2010).
[3] R. L. Hughes, The flow of human crowds. Annual Review of Fluid Mechanics 35 (2003) 169-182.
[4] D. Helbing, Quantitative sociodynamics: stochastic methods and models of social interaction processes (Springer 2010).
[5] K. Popper, The logic of scientific discovery (Routledge, 2005).
[6] N. Silver, The signal and the noise: why so many predictions fail, but some don't (Penguin, 2012).
[7] D. Lazer, et al., Life in the network: the coming age of computational social science, Science 323 (2009) 721-723.
[8] D. V. Shah, J. N. Cappella, W. R. Neuman, Big data, digital media, and computational social science: Possibilities and perils, The ANNALS of the American Academy of Political and Social Science 659 (2015) 6-13.
[9] R. J. Fisher, Social desirability bias and the validity of indirect questioning, Journal of Consumer Research 20 (1993) 303-315.
[10] V. Mayer-Schonberger, K. Cukier, Big data: a revolution that will transform how we live, work, and think (Houghton Mifflin Harcourt, 2013).
[11] S. D. Gosling, P. J. Rentfrow, W. B. Jr Swann, A very brief measure of the Big-Five personality domains, Journal of Research in Personality 37 (2003) 504-528.
[12] S. Battiston, et al., Complexity theory and financial regulation, Science 351 (2016) 818-819.
[13] C. M. Reinhart, K. S. Rogoff, The aftermath of financial crises, American Economic Review 99 (2009) 466-472.
[14] J. Y. Lin, New structural economics: A framework for rethinking development and policy (The World Bank, 2012).
[15] M. S. Granovetter, The strength of weak ties, American Journal of Sociology 78 (1973) 1360-1380.
[16] J. P. Onnela, et al., Structure and tie strengths in mobile communication networks, PNAS 104 (2007) 7332-7336.
[17] P. S. Park, J. E. Blumenstock, M. W. Macy, The strength of long-range ties in population-scale social networks, Science 362 (2018) 1410-1413.
[18] Y. LeCun, Y. Bengio, G. Hinton, Deep Learning, Nature 521 (2015) 436-444.
[19] J. E. Blumenstock, Fighting poverty with data, Science 353 (2016) 753–754.
https://blog.sciencenet.cn/blog-3075-1162207.html
上一篇:H++, H=69
下一篇:电子科大大数据研究中心硕士生陈维龙荣获WSDM大赛冠军