博文
巧挖科学博客之均击量公式,兼谈干预规则----趣味数据挖掘之四
 精选
精选
|||
巧挖科学博客之均击量公式,兼谈干预规则----趣味数据挖掘之四(唐常杰)
讲过长课的老师,常在受众将发生审美疲劳之时段,安排一点有趣的内容。为消除疲劳,现来一段有趣的、与博友的自尊心和荣誉感相关的博文,议题是:挖掘科学博客的平均点击量公式,以及提高平均点击量的方法。
1 平均点击量排行引出的问题 嘤其鸣矣,求其友声,作者总希望读者多一点,博主们希望点击量排行高一点,朴素而自然。打开科学网主页排行榜,看总排行的Top 4 ,点击量区间为[6百万, 9百万] ,这些资深博主起步早,博历高,博文篇数达到几千甚至上万。
如果某位晚起步几年的新博主,立志要进入总排行Top 4,估计有两种结果:(a) 把青春献给博客, 成功了,那将是一首科博青春之歌;(b)甜蜜的梦容易醒,梦醒了,放弃了;
如果修改一下目标,把追求目标从总排行改为周排行或均排行,则是比较现实可行的。
周排行描述短期行为,博主像脉冲星爆发那样,在一周中发一篇或连续几篇预先准备的好博文或耸人听闻的事件或评论,就可灿烂一周。事实上,在博客上常见到超新星的爆发。
如欲提高平均点击量(简称均击量),首当其冲的问题是:科学博客的均击量是怎样计算的?知道了这个计算规则,再看看其有什么启发,思考提高均击量的方法。
不需托人打听,不需后门询问, 下面以科学网公开的数据,以博主的合法的手段,挖掘出科学博客均击量公式。然后讨论提高均击量的方法。
2 均击量不是简单平均 记平均点击量(Average)为A,总点击量(Total)为T,博文(Blog)总数为B,随便找一位博龄大于一年的博友数据,简单计算会发现,与常识不同,A≠ T/B.
于是猜测,科学网为鼓励博主立新功,而不躺在功劳簿上吃老本,对点击量做了加权处理,有多种可能,例如
(a) 只用最近几个月的博文参加均击量计算。
(b) 复杂一些,用加权,时间远的博文权重小,近的博文权重大;
从简单到复杂探索,如果简单的想法能解决问题,就不考虑复杂的。
3. 投石冲破水中天,两分钟的干预实验: 似乎已知条件太少,不妨学一回苏东坡,故事中,当秦少游因为苏小妹的“闭门推开窗前月”而困惑时,苏学士“投石冲破水中天”,使其豁然开朗。从干预规则挖掘的观点看[1],投石是向一个稳定系统施加干预,在战争片中称为火力侦察,在谍战片中称为“打草惊蛇”,当一个系统对干预作出响应时,其响应就提供了新的、具有动力学性质的信息。
笔者昨天在自己的博客上做了一个干预实验,增加了一篇测试性质的空博文。
标题: “测试平均点击量的空博文”,
隐私设置:草稿隐藏;
评论设置: 不允许评论。
科学博客系统的响应了这一干预,记录在下列表格中,三分钟后删去此博文。
| 总点击量 | 平均点击量 | 参与平均的有效点击量 |
发博文之前一分钟 | T1=548723 | A1=5541 | y1 (未知) |
发博文之后一分钟 | T2=548730 | A2=5243 | y2(未知) |
4.1 先说明,y2-y1 ≈T2-T1 。整个测试大约两分钟,此期间新发生的点击量,包括礼节性回访等,不会太多,如果点击的是近期博文,属于有效点击量,其效果会被A2吸收,如果点击的是很早的博文,有点干扰也不大。实验中 T2-T1 =7,容易理解|y2-y1| < |T2-T1| =7。所以,即使发生了干扰,也不大。
设参与均击量计算之博文数量是X篇, 容易得到下列方程组:
y1=A1*X, (1)
y2=A2*(X+1) (2)
两式相减,得到:
T2-T1≈y2-y1= A2(X+1)-A1*X
解方程,代入上面表格中数值
X≈(A2+T1-T2)/(A1-A2)=(5243-7)/(5541-5243)=17.6
X是整数,所以X= 18
4.2 实验结果有两种解释:
(a).科学博客取最近18篇博文计算均击量;或者,
(b).取最近M个月的博文计算均击量,推断M=6,方法如下:
检查了最近18篇博文中最前面一篇,是2011年6月开始的,这说明5月份及更早的博文已经过期,不再参加平均点击量计算了。这说明科学网取最近6个月的博文计算均击量,(谢谢27楼的提示)。
数据挖掘就像在猜测自然与社会之谜,有时如盲人摸象,摸到了大象耳朵。例如,科学网也可能还有其他的规则,按博龄划线,博龄长的,参与均击量的区间长一点,以体现对资历的人性化照顾;或者过期期限是按周来计算的,就像猜谜,有时有多种言之成理的猜测,说不定不同博友会挖出不同的公式(静候博友反馈),。
此外,挖掘结果与锄头落的地方也相关,挖出来的可能只是局部规律,还需要多方检验,
如果多有一些博友来参与实验,经过几番讨论和校正,就可逐渐逼近真实。
到底是哪一种,先不做最后结论,静候博友反馈,但其共性,已够我们思考提高平均点击量的策略了。
4.3 作干预实验须知, 为减少干扰,要注意:
(a)不要在每月最后一天,或第一天做,那可能与科学网的规则更换期碰撞,增加误差。
(b) 不要在刚发了一篇好博文时做,那可能在做实验的两分钟内,就有对新旧博文的大量点击,可能增加误差。
(c ) 干预实验也可以通过删除一篇博文来做,不过实验表明,删除一篇文章后,需要稍微长一点的时间(5-15分钟),才能看到平均点击量增加, 其间,对旧博文的点击可能产生较大误差,而用增加博文的方式较快较准。
5 这是数据挖掘吗?当然是,上述过程符合对数据挖掘的描述:从数据中发现隐藏的、有趣的,有意义的知识。只不过因为问题简单,杀鸡焉用牛刀,用手工就做出来了。 其次,所用的方法是我们提出的干预规则相关的方法。文献[1]中对干预规则有详细介绍,不在此赘述,如有可能,或另择机科普。在后面列出的相关博文《 5 科技春耕时节的那道风景线-----基金漫谈》 中,也讨论过对自然科学基金批准率的干预。
6 公式发现技术的应用
6.1 均击量规则的指导作用,博主可以从下列方面努力,提高平均点击量排行(没有投机取巧):
(a).可持续发展,细水长流,不断有新博文,科学博客鼓励立新功,不鼓励吃老本。如果连续 M个月不发博文,就坐吃山空了,理论上,平均点击量为0或接近0(不知猜测是否正确),当然总点击量还在;
(b) 打观点牌或见解牌。独到的见解,新奇的观点,引人争议的观点,常有高点击量。
(c) 打事件牌。报道重大的事件,并有中肯的评论
(d) 宁可少一些,也要精一些,新博主可从一开始就走精品路线。即使不是热题,好科普,好摄影、好诗,好散文(例如博主YC的博文),也是很耐读的,时效长,常有回头客。
(e) 去粗存精。如果某一篇近期博文点击量大大低于平均值,且无重要内容,删去它,可提高均击量;注意,删除远期博文不能增加平均点击量,只会减少总的点击量;
(f) 如本博文,有相关博文的链接,按照上面挖掘的结果,最好是链接那些近期的博文;博友点击后,既增加总的点击量,也增加平均点击量。而如果博友点击远期博文,只增加总点击量,不增加平均点击量。
6.2 公式发现或规则发现有重大实用价值
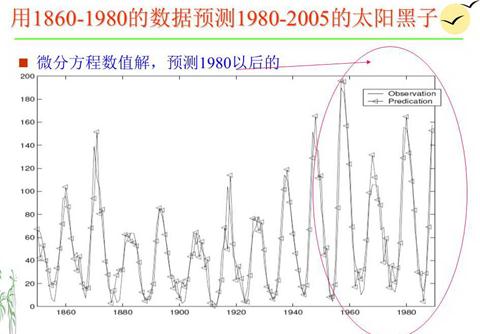
举例说明,我们在文献[2]中,用基因表达式编程(Gene Expression Programming)的方法,从太阳黑子1860-1980年的数据数据中挖掘出微分方程 :
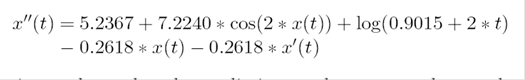
解这个微分方程,得到函数,用来预测 1980年-2005年的太阳黑子,得到很好的拟合。如下图所示
更复杂的例子,不太容易用来做科普了。
7 数据挖掘研究者反对狗仔队 数据挖掘研究者可能会养成职业习惯,看见了数据,就想挖掘数据背后的规律。上面演示了用合法手段,从公开数据中挖出了均击量计算规则的过程,相信是无害的。
网上有很多敏感数据可能放得不够谨慎,不需深挖,就能得到。例如,网上药店可能存储有用户浏览的记录,药店老板的儿子略施小计,推测出某位公众人物常浏览治疗性病的药物,实事求是地在微博上发一条消息,被好事者转发,信息在传递中发生畸变,当其从小报的狗仔队再转发出来时,增加了无限的遐想或胡说八道,损害了个人隐私。在一个长长的转发链上,该谁来吃官司呢?
如果药店老板透露了某位大人物之子每次探望这位大人物前都关注某癌症药物的消息,信息畸变后,说不定会引起股票震荡,甚至政治上的暗流涌动,这说明,敏感人物的家属的网络行为也属于反数据挖掘的隐私保护对象。
有需求就有研究,数据挖掘研究者不会与狗仔队为伍,义不容辞地承担起研究“信息畸变”、“反数据挖掘”、“防止挖掘的隐私保护”等课题,如有可能,或会另择机科普。
(看27楼提示后补充:原没留意到27楼提示的那个脚注。此文演示了一个基于干预的挖掘方法,即使没那条信息,也能挖掘出来)。
参考文献
[1] 段磊,唐常杰, 杨宁,左劼,王悦,郑皎凌,徐开阔: "干预规则挖掘的概念、任务与研究进展", 计算机学报,Vol. 34 No,10 , P 1831- 1842 ,2011.10 , EI检索。
[2] Zuo Jie, Tang Changjie ,Li Chuan , Yuan Chang-an and Chen An-long,? "Time Series Prediction based on Gene Expression Programming", WAIM04 (International Conference for Web Information Age 2004). LNCS (Lecture Notes In Computer science) Vol.3129, pp.55-64, edited by Q Li and G. Wang, Springer Verlag Berling Heidelberg??2004.8,ISBN 3-540-22418-1?? (EI 检索)
相关博文
3 一篇它引上万的大牛论文与数据血统论-- 趣味数据挖掘之三
4 巧挖科学博客之均击量公式,兼谈干预规则----趣味数据挖掘之四
5 听妈妈讲 过去的故事,分房与分类-----趣味数据挖掘之五
8 农村中学并迁选址、K-平均聚类及蛋鸡悖论--趣味数据挖掘之八
9 灯谜、外星殖民、愚公移山和进化计算---趣味数据挖掘之九
10 达尔文、孟德尔与老愚公会盟:基因表达式编程--趣味数据挖之十
11 十大算法展辉煌,十大问题现锦绣---趣味数据挖掘之十一
科技春耕时节的那道风景线-----基金漫谈 (这篇博文讨论过对基金批准率的干预)
假日聚会,戏说云物人海 --漫谈大数据
https://blog.sciencenet.cn/blog-287179-516090.html
上一篇:一篇 "它引" 上万的大牛论文 与 数据血统论-- 趣味数据挖掘之三
下一篇:双模校车:至少我们还有梦