博文
NDVI时间序列分析之Sen+MK分析全过程梳理
||
NDVI时间序列分析之Sen+MK分析全过程梳理
Sen斜率估计用于计算趋势值,通常与MK非参数检验结合使用,即先计算Sen趋势值,然后使用MK方法判断趋势显著性。
原理
Theil-Sen Median方法又被称为Sen斜率估计,是一种稳健的非参数统计的趋势计算方法。该方法计算效率高,对于测量误差和离群数据不敏感,常被用于长时间序列数据的趋势分析中。
β=mean(xj−xij−i),∀j>i
式中:xj 和 xi 为时间序列数据。β大于0表示时间序列呈现上升趋势;β小于0表示时间序列呈现下降趋势。
Mann-Kendall属于非参数检验方法,与其他参数检验的方法相比,不需要样本遵从一定的分布,受异常值干扰小,更适合顺序变量。Mann-Kendall检验已经在水文、气象趋势变化相关研究中得到了大量的成功应用,用于判断径流、降水、气候等的变化趋势的显著性。
R语言Sen+MK计算
R语言使用Raster包进行栅格计算,利用trend包sen.slope函数进行sen+mk的计算。对于下面代码的阅读,一定要看代码帮助!代码如下:
library(sp)
library(raster)
library(rgdal)
library(trend)
library(terra)
#输入一个文件夹内的单波段TIFF数据,在这里是历年的NDVI年最大值
flnames <- list.files(path = './yearmax/', pattern = '.tif$')
fl <- paste0("./yearmax/", flnames)
firs <- raster(fl[1])
for (i in 2:34) {
r <- raster(fl[i])
firs <- stack(firs, r)
}
fun <- function(y){
if(length(na.omit(y)) <34) return(c(NA, NA, NA)) #删除数据不连续含有NA的像元
MK_estimate <- sens.slope(ts(na.omit(y), start = 1982, end = 2015, frequency = 1), conf.level = 0.95) #Sen斜率估计
slope <- MK_estimate$estimate
MK_test <- MK_estimate$p.value
Zs <- MK_estimate$statistic
return(c(Zs, slope, MK_test))
}
e <- calc(firs, fun) #栅格计算
e_Zs <- subset(e,1) #提取Z统计量
e_slope <- subset(e,2) #提取sen斜率
e_MKtest <- subset(e,3) #提取p值
plot(e_Zs)
plot(e_slope)
plot(e_MKtest)
writeRaster(e_Zs, "./Sen+MK/e_Zs.tif", format="GTiff", overwrite=T)
writeRaster(e_slope, "./Sen+MK/e_slope.tif", format="GTiff", overwrite=T)
writeRaster(e_MKtest, "./Sen+MK/e_MKtest.tif", format="GTiff", overwrite=T)
如果还没明白,下面二维码推荐一个培训班,有专门的R语言老师带着学习:
NDVI趋势制图
前面R语言计算完slope和Z值后,根据这两个结果就可以进行NDVI趋势制图了。
变化趋势划分
结合SNDVI和Z统计量划分NDVI变化趋势:
slope -0.0005~0.0005稳定区域 大于或等于0.0005植被改善区域 小于-0.0005为植被退化区域 Z统计量 Slope划分
置信水平0.05 Z绝对值大于1.96显著 Z绝对值小于等于1.96不显著 Slope被划分为三级: SNDVI≤−0.0005 植被退化 −0.0005≥SNDVI≥0.0005 植被生长稳定 SNDVI≥0.0005 植被改善 使用重分类(Reclassify)对slope进行划分 由于slope.tif文件研究区范围外的值非空,所以在这里先裁剪了一下 裁剪所用矢量和栅格数据坐标系需要一致,否则范围容易出错 统一使用了WGS84地理坐标系作为空间参考 使用Model builder构建地理处理流
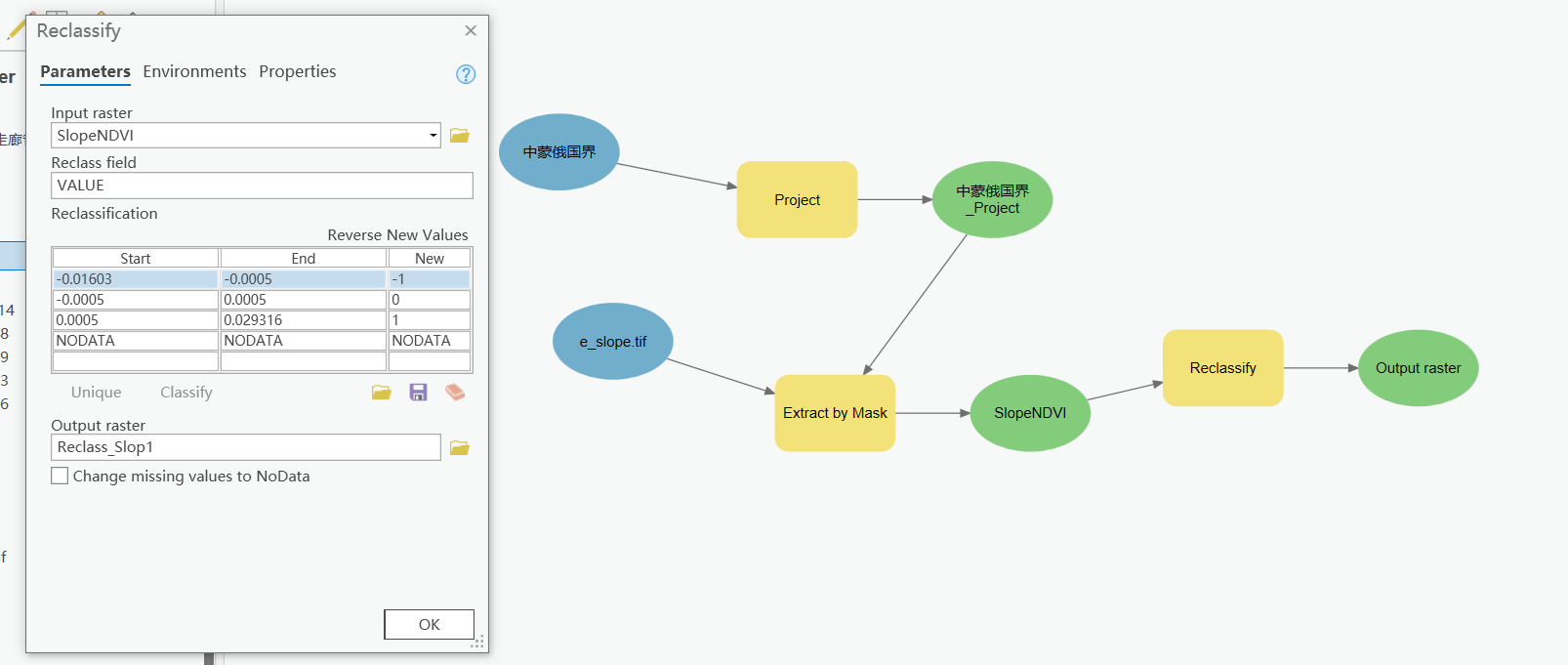 Slope划分过程
Slope划分过程
重分类结果: -1退化 0稳定 1改善
Z值划分
对Z值进行重分类,确定显著性 |Zs|≤1.96 未通过95%置信度检验,不显著 |Zs|≥1.96 通过95%置信度检验,显著
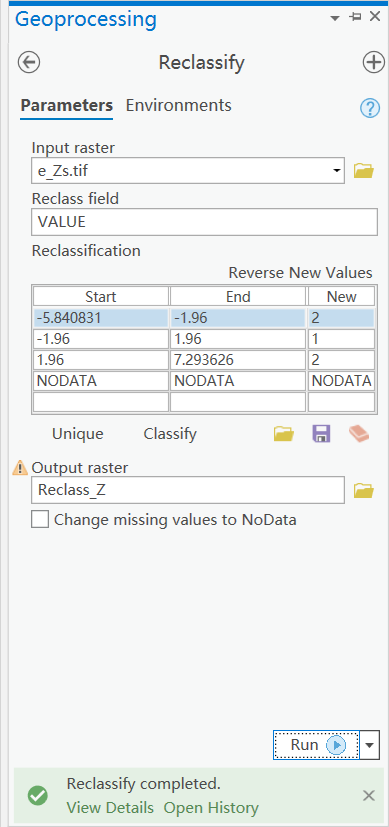 Z值重分类
Z值重分类
重分类结果: 1不显著 2显著
变化趋势计算
使用栅格计算器将Slope和Z值计算结果相乘,最后得到趋势变化划分
-2严重退化 -1轻微退化 0稳定不变 1轻微改善 2明显改善
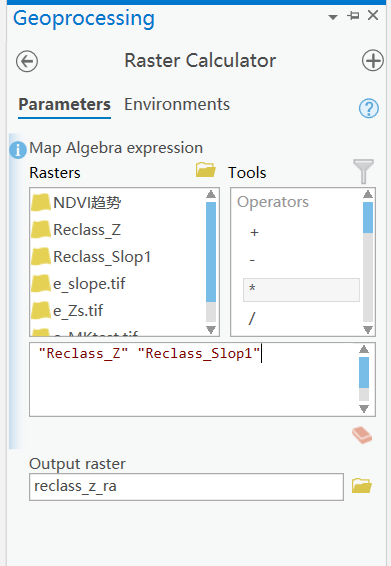 栅格计算器相乘
栅格计算器相乘
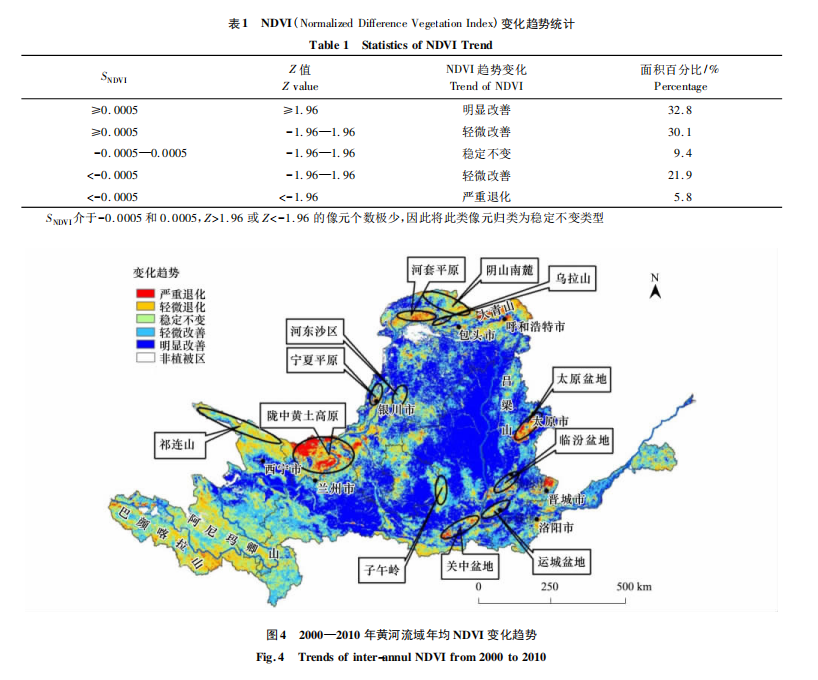
对计算完成后的栅格属性表里面不同种类的像元数进行统计,如此即可获得下面的NDVI变化趋势统计图表。
参考文献
袁丽华, 蒋卫国, 申文明, 等. 2000—2010年黄河流域植被覆盖的时空变化[J]. 生态学报, 2013, 33(24): 7798–7806. NDVI时间序列分析原理与实现(CV和Sen+MK趋势分析) 【文献阅读笔记】Sen+MK NDVI趋势分析的一些问题 基于Sen+MK的NDVI变化趋势统计分析 【文献阅读笔记】黄河流域植被变化时空分析
https://blog.sciencenet.cn/blog-2438290-1276507.html
上一篇:【更新108篇】有不会的GIS、遥感、景观指数、R语言问题,记得从这里面搜一下