博文
IEEE TFS主编Jon Garibaldi:建立模拟人工推理的模糊专家系统
|
IEEE TFS主编Jon Garibaldi:
建立模拟人工推理的模糊专家系统
原创: 陈虹宇
由中国自动化学会和中国科学院自动化研究所复杂系统管理与控制国家重点实验室联合主办的2018年第二期(总第二十六期)“钱学森国际杰出科学家系列讲座”于5月17日在中科院自动化研究所顺利举办。本期讲座邀请到英国诺丁汉大学计算机科学系教授Jonathan Garibaldi以“Beyond Type-1 Fuzzy Systems, and Beyond the Type-2 Centroid” 为题进行演讲报告。当前,Type-2模糊集与系统作为模糊领域研究者的重要工具,可以部署在广泛的应用程序中。Jonathan Garibaldi教授将介绍一些目前在诺丁汉大学进行的关于人工推理建模的Type-1以及Type-2的相关研究,包括更多使用Type-2建模能力的方法。

Jonathan M. Garibaldi教授于1984年毕业于英国布里斯托尔大学(Bristol University,UK)物理系,并在1990年和1997年分别获英国普利茅斯大学(University of Plymouth,UK)智能系统理学硕士学位和博士学位。他是英国诺丁汉大学计算机科学系的负责人,领导智能建模与分析(IMA)研究小组,并且是高级数据分析中心(ADAC)的创始人。他的主要研究兴趣是医学领域的建模不确定性和人工推理变异。他在模糊集与系统以及实际应用领域作出了许多贡献。Garibaldi教授发表了200余篇关于模糊系统和智能数据分析的论文,目前是IEEE模糊系统汇刊(IEEE Transactions on Fuzzy Systems)的主编。他在许多国际性的委员会任职,如FUZZ-IEEE,WCCI,EUROandPPSN。
报告主题
Beyond Type-1 Fuzzy Systems, and Beyond the Type-2 Centroid

报告内容

主持人王飞跃教授:
今天非常荣幸能够邀请到Jonathan Garibaldi教授为我们进行讲座。Jonathan Garibaldi教授是英国诺丁汉大学、宁波诺丁汉大学计算机科学系的负责人,同时也是IEEE Transaction on Fuzzy Systems的主编。今天,他将为我们讲解他在关于Type-2模糊系统方面研究的相关内容。对于Type-2模糊系统,我期待越来越多的人能够投入其相关研究当中,因为对于现在炙手可热的AI来说,它是一项可以支撑智能决策以及自然语言处理的非常好的技术。希望通过本次讲座,你们能够进一步了解Type2并在今后的研究中对其加以运用,从而获得更加丰富的研究成果。接下来,让我们欢迎Jon带来精彩的讲座。
主讲嘉宾:
谢谢王教授的热情介绍。我很荣幸今天能够来到中国科学院自动化研究所进行本次讲座,非常感谢你们诚挚的邀请。正如王教授刚才所说,Type-2模糊系统是模糊理论研究中最活跃的领域之一。如果你们正在进行模糊系统中一些相对复杂内容的研究,特别是针对真实的经验知识、系统体系和人类活动进行建模的研究,那么我建议你们采用Type-2模糊系统。
鉴于本次讲座的主要目的是学术知识分享推广而不是数学理论分析推导,所以我将以图片的形式进行内容的展示和阐述。讲座的题目定为“Beyond Type-1 Fuzzy Systems, and Beyond the Type-2 Centroid”,是因为目前有很多系统既不属于Type-1也不属于Type-2,而是介于两者之间。针对这些系统,我将举例对相关研究和应用情况进行说明和介绍。
首先,在讨论模糊系统之前,我想谈谈促使我研究模糊系统的原因。
专家变化——新生儿身体状况的即时评估
Expert Variation--Immediate Neonatal Assessment
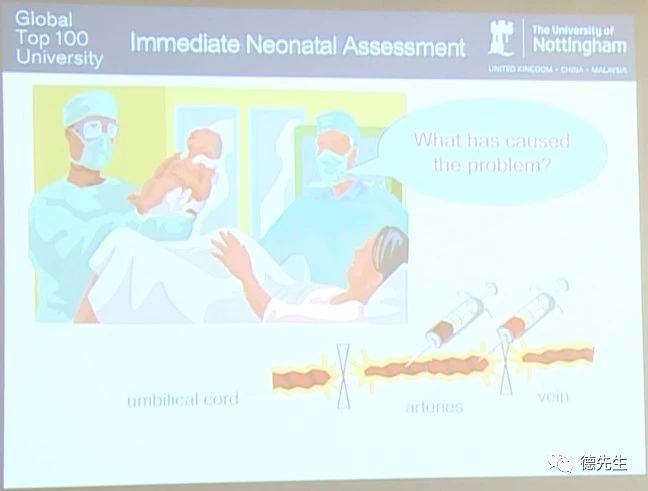
专家变化(Expert Variation),是一种人们工作和研究的方式,类似于微小的变化波动。我刚开始攻读博士学位时是在联合学院,同时进行与计算机科学和医药科学相关的研究。实际上,当时我在医院产房旁边的办公室开展研究工作,研究的主要内容是婴儿健康状态的评估。更确切的说,是婴儿在刚降生时的身体状况评估。我们尝试分析和判断新生婴儿的生理功能是否受到损害或存在缺陷,并得出分娩结果。由于时间限制,在这里我不对具体医疗细节进行详细阐述。简而言之,分娩过程不管对产妇还是婴儿来说都是非常有压力的。
通常来说,婴儿在分娩过程中极其容易缺氧。脐带(umbilical cord)连接子宫和婴儿,同时为婴儿传输氧气。婴儿获得氧气后通过持续的新陈代谢以维持生命活动。而新陈代谢所产生的废物(二氧化碳和其他代谢产物)由脐带传输回到母体的血液中,由母体通过呼吸进行氧气和二氧化碳的交换。
在分娩过程中,子宫进行间歇的收缩活动以将婴儿排出体外,而每次收缩都会导致氧气供应的临时切断,类似于间歇性地屏息。在分娩初期,收缩活动大概每5分钟进行一次,每次持续30s。大致等同于屏息30s后休息5分钟,这种频率婴儿是可以忍受的。而到了分娩后期,随着婴儿临近排出体外,收缩活动大概每隔1分钟就要进行一次,每次持续长达1分钟,这就像是屏息1分钟后休息1分钟。你们可能觉得这没什么困难,认为自己能够轻易做到。但如果尝试将这种活动持续进行4个小时,我可以肯定地说你们是做不到的,你们无法忍受这种频度的缺氧。
每次进行屏息和呼吸时,新陈代谢产物在体内的循环会导致血液中氧气含量不断降低,同时二氧化碳含量持续升高。成年人经过长达4小时的上述活动后将会死亡,而婴儿必须适应这种缺氧状态,因为缺氧是正常分娩过程中的一部分。但如果婴儿被固定或缠住了而无法正常呼吸,这时将会发生什么呢?颈部被缠住时,首先身体会产生抽搐现象。随后,缺氧状态将导致除心脏和大脑外所有器官逐渐停止正常功能活动。如果持续处于缺氧状态,那么大脑将会受损并最终衰竭。而这种情况有可能在分娩过程中出现。
即使在发达国家,婴儿的健康降生也仍然存在风险,大概有5‰的婴儿最终会在分娩过程中死亡。其中,大约有40%-50%的婴儿确诊为脑死亡。同样,产妇也处于危险之中,其死亡率约为2%-3%。虽然危险相对较小,但发生的可能性仍然存在。在大多数情况下,急救能够挽救婴儿的生命。但分娩过程的危险不仅可能由缠在脖子上的脐带所引起,也可能由产道的堵塞或者胎位不正等情况所导致,这都会影响婴儿正常生命活动的空间区域。医务人员会实施剖腹产等一系列措施进行抢救,但有时由于分娩过程持续过长,婴儿将会遭受脑部损伤而最终死亡。
上述情况都有可能会发生,并且可以说都是非常严重的身体问题。所以我们和一支领域内世界顶尖的研究团队一同在病房里进行相关研究工作。我们想知道,婴儿在刚出生的时候,准确地说是在其进行自主呼吸前,其脑部是否存在受损情况?当然,直接询问婴儿或对其进行常规脑部检查都是不可行的,那么该如何检测呢?
在婴儿的降生后到自主呼吸前的这段时间中,大概1-2分钟左右,研究人员利用类似的小型塑料夹子,分别夹住脐带与婴儿和母体连接的两端。具体来说,分别用两个夹子夹住脐带的每一端,并在夹子间分别将其从两端切断,最终得到一小段约为10cm长的脐带。婴儿与母体分离后,母体及胎盘将继续进行后续医疗处理,例如胎盘的取出等措施。同时,因为脐带被夹住时婴儿还没有进行自主呼吸,所以这时可以从脐带中获得传输给婴儿以及婴儿排出的血液,即对所得脐带的动脉(arteries)和静脉(vein)进行血液采样和分析评估。值得一提的是,婴儿体内的氧气在静脉而不是动脉中传输,这与成人刚好相反。而随着婴儿的降生,氧气将在通过心脏后改变循环方向。
专家变化——评估难点
Expert Variation--Difficulties with Assessment

血液样本采集完毕后,将其放入血液气体分析机。根据血气机的分析结果,基本上可以判定婴儿的身体状况。血气机主要用于检测和判定血液的酸性pH和其他与乳酸相关成分的含量。
首先,对于血液的酸性pH,二氧化碳(C2O)作为新陈代谢的产物与水(H2O)发生化学反应后会生成碳酸(H2CO3),其能够使血液的酸性变强,即pH降低。所以pH越低则说明二氧化碳含量越高。其次,对于碱缺失(Base Deficit,BDect),其能够反映乳酸物质的含量。乳酸是血液中的另一种酸,其由无氧代谢产生。有氧代谢是在氧气供应充足条件下进行的新陈代谢活动。无氧代谢则是在氧气供应不足条件下进行的新陈代谢活动。有氧代谢会产生二氧化碳,而无氧代谢会产生乳酸物质。如果进行体育锻炼或健身,例如肌肉锻炼、俯卧撑或短跑,肌肉将会产生疼痛感。这种疼痛由肌肉中的乳酸所导致,也就是由无氧代谢所导致。所以,缺氧不仅会导致血液的流动方向的改变,即最终只为心脏或大脑供应氧气。同时也会导致新陈代谢方式的改变,即从有氧代谢转变为无氧代谢。这种转变机制的目的是尽量保持新陈代谢的持续进行,使其能够在无氧的情况下继续维持一段时间。
总而言之,分析判定新生婴儿的身体状况需要4个参数的数值,即分别从动脉和静脉血液中所检测的pH和BDect。对医生来说,根据参数数值即可推断婴儿的身体状况,判断其是否因脑损伤或缺氧而濒临死亡。所以测定上述4个参数的数值并将其提供给医生,就可得知婴儿的健康状态。
而事实证明,人类只能勉强分析三维数据,难以根据四维数据进行推断。这是一个非常艰巨的任务,因为人类无法构思分析四维图像。所以判定婴儿身体状况的过程听起来简单,实际上却并不那么简单。
当时我们同一些世界顶尖的专家一起工作,他们已经针对这个课题发表了相关研究论文,了解该如何对其进行分析判断。毫无疑问,我们希望能够分析和推断每一次的分娩结果。但每时每刻都有婴儿降生,专家无法做到时刻在各个病房待命,所以我们想要开发一个计算机专家系统来完成这项工作,实现对血液气体进行解析并向医生或非专业人士报告婴儿的身体状况。
专家变化——模糊专家系统
Expert Variation--Fuzzy Expert System

如上图所示,根据专家们的研究成果,我开发了一套能够实现上述功能的模糊专家系统(Fuzzy Expert System),并将其置于医院使用。位于图片左边的设备是血液气体机,其与中间运行专家系统的计算机相连接,最终的分析结果通过右边的打印机打印出来。
有人可能会问,如何确定这个系统的结果是否可靠有效?
我认为有效性有两种定义。其一,可靠有效在某种意义上是指系统是否存在漏洞、是否会出现崩溃的状况。其二,其指系统所得分析结果的正确性。当然,模糊专家系统并不会崩溃,但作为领域内世界上第一个模糊专家系统,如何证明其有效性或者说其结果的正确性呢?如果是你们会怎样评估世界上第一个系统呢?
根据之前所说,我所在的研究团队中有6位世界顶尖的研究专家。所以我唯一想到的评估方法是,将一些案例数据提供给团队中的人类专家,得到其分析判定婴儿的身体状况结果。同时,把相同的数据提供给计算机模糊专家系统并观察其所得分析结果。也就是说,将计算机专家系统与人类专家进行比较。
首先,我非随机地选择了50个患病婴儿的案例,请团队中的6位专家分别独立对这50个病例的身体状况进行排序。序列1代表病情最严重的婴儿,序列50相应地代表身体相对最健康的婴儿。与此同时,我将相同的病例数据输入到模糊专家系统中。实验最终得到以下结果:
专家变化——案例结果
Expert Variation--Example Results
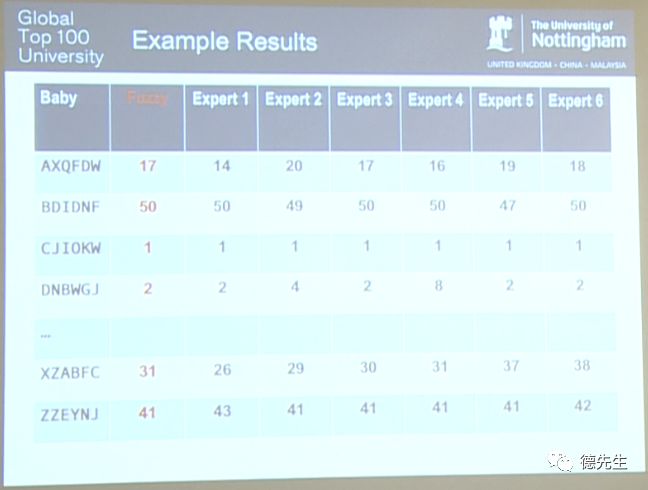
举例来说,6位专家(Expert1-Expert6)均将位于第三行的病例婴儿(Baby)列为序号1,判定其为病情最严重的婴儿。同时可以看到,专家系统(Fuzzy)也将其判定为序号1。而对于其他婴儿病例,专家们和系统所得的结果则存在或多或少的差异。随后,我又将结果整理为下图形式进行展示。
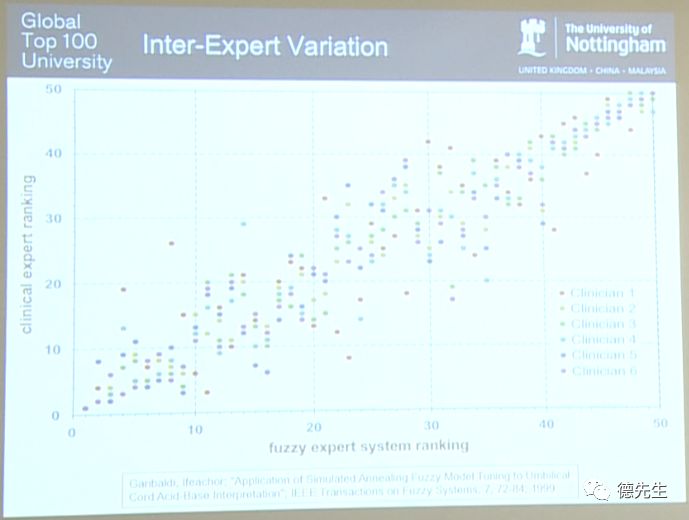
这张图直观地反映了专家之间的判定结果变化(Inter-Expert Variation)。图中,位于X坐标轴的数据是模糊专家系统所给出的排序结果(fuzzy expert system ranking)。系统将序号1判定为身体状况最差的婴儿病例,我在这个位置(左下角)用一个圆点进行标记表示。位于Y坐标轴的数据是人类专家所给出的排序结果(clinical expert ranking),均由6位专家(Clinican1-Clinican6)自行标记。我们可以看到有6个圆点被重叠标记在序号1的位置。所以,专家系统和6个人类专家均将这个婴儿判定为序号1,即均认为其病情最为严重。需要说明的是,以上病例数据均为从现实中的医院获取的真实数据。事实上,经过血液样本的采集和分析后,1号婴儿最终不幸去世。这是唯一死亡的婴儿,所以毫无疑问其病情是最严重的。
接下来,以系统所判定的10号婴儿为例进行说明。对于10号婴儿,人类专家们分别将其病情判定为序号6、11、12、13、15。同一婴儿病例所对应的不同数字结果反映出他们对于病情判定问题持有不同的观点和看法。
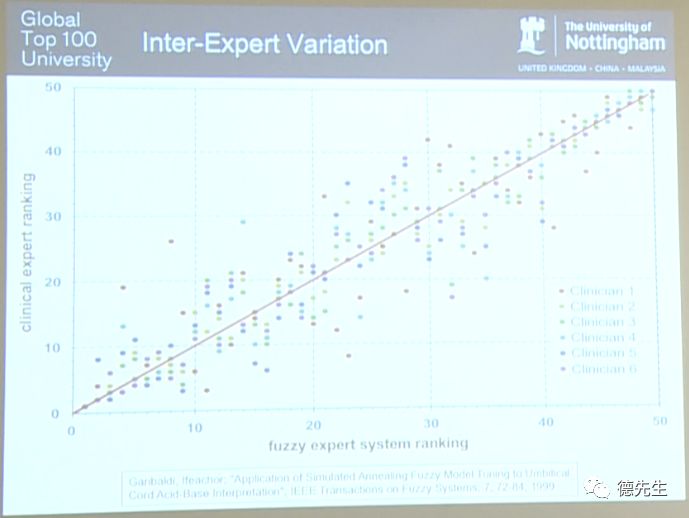
如果团队中所有的专家都能够达成意见一致,则每个病例的所有判定结果将全部重叠在一起并沿如上图所示的直线排列,这种情况是非常完美的。但不难发现,所得结果并不尽如人意。甚至有一些病例在图中对应了6个不同位置的圆点,也就是说6个人类专家给出了6个不同的判定结果。
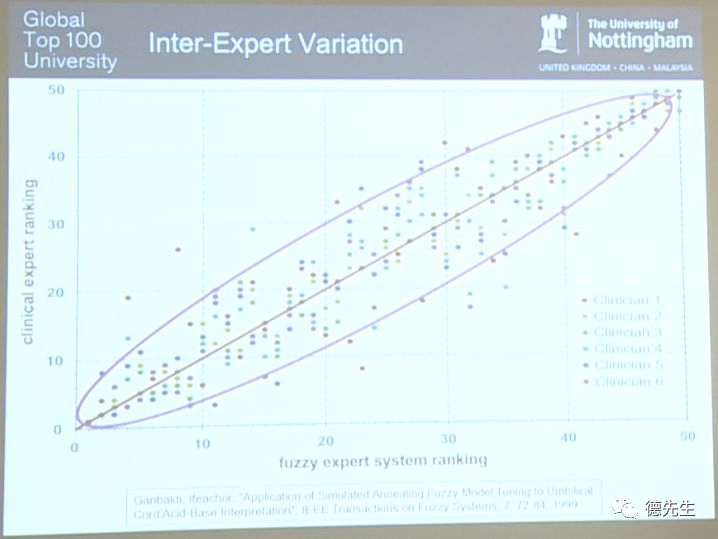
在上图中,所有的判定结果圆点散布在直线周围,我们将这种情况称为专家间变化(Inter-Expert Variation)。对于困难的决策问题,有时人类会给出不同的答案。以上实验结果充分反映了这个现象。这引发了我进一步研究的兴趣,于是我又进行了另一项实验。
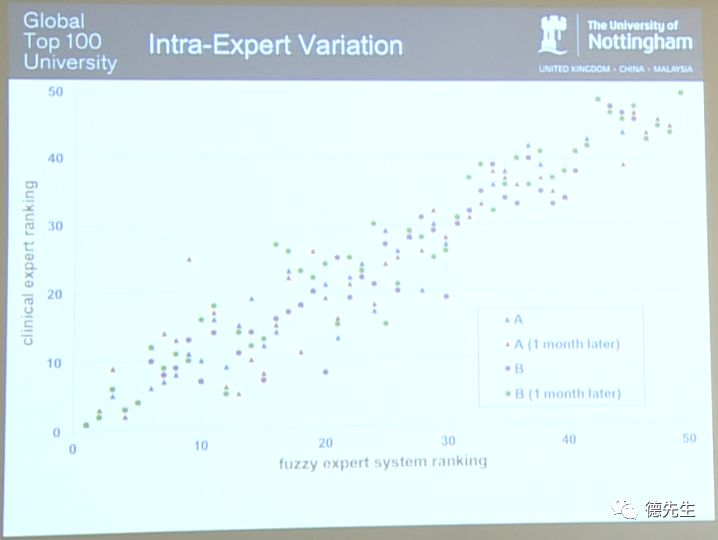
在这项实验中,我随机挑选了两位自愿的人类专家进行两次病例评定实验,以观察专家内部的判定结果变化(Intra-Expert Variation)。两次实验所用数据完全相同且时间间隔为一个月,最终两位专家所得实验结果分别在上图中用A和B表示。不同颜色的三角形和圆形分别代表专家A和专家B在第一次实验和一个月后第二次实验中的所得结果。
可以看到,序号1的标记图形是由两个三角形和两个圆形同时叠加在一起所组成。再次说明一下,这是最终死亡的婴儿,显然他的身体状况非常差。对于专家系统排列的序号2病例,A和B给出了不同的标注意见。对于序号3,B在两次实验中所得结果相同,而A则分别将其排为序号5和序号9。但不仅只有A,图中也存在A和B针对同一病例均给出不同结果的情况。换句话说,A和B均与自己产生意见分歧。
所以对于复杂困难的决策问题,人类有可能会不同意自己曾经所做出的判断。而模糊专家系统与人类专家不同,其可以得到完全相同的结果。下图为模糊专家系统间变化(Intra-FES Variation)。
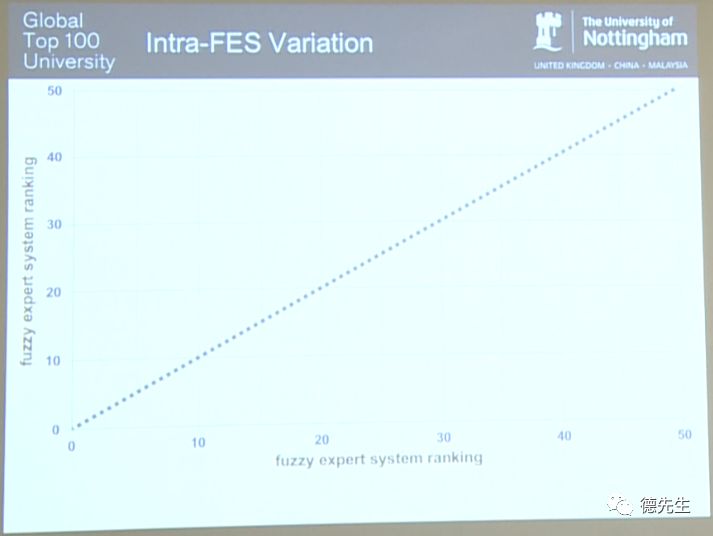
大多数人会说,我希望在应对复杂问题时所得结果总能保持正确和一致,这促使我开始思考以下三个问题:

(1)我们能否对专家变化进行衡量或建模?
(2)我们能否使用这些模型改善基于计算机的决策性能?
(3)我们能否开发能够帮助专家评估风险的决策支持系统?
模糊——Type-1模糊集并不“模糊”!
Fuzzy--Type-1 Sets are not ‘Fuzzy’!
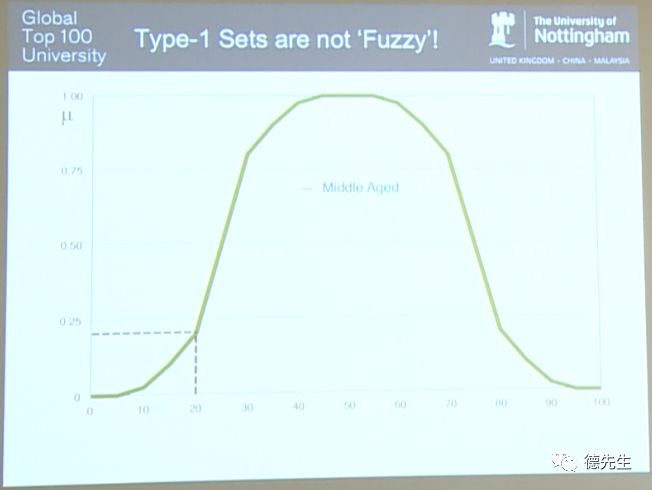
接下来,我们来谈谈“模糊”。举一个简单的例子,上图为一个描述中年人(Middle Aged)年龄的模糊集合的隶属函数,其中X坐标轴表示年龄,Y坐标轴表示隶属度(μ)。举例来说,60岁的年龄对应为中年。
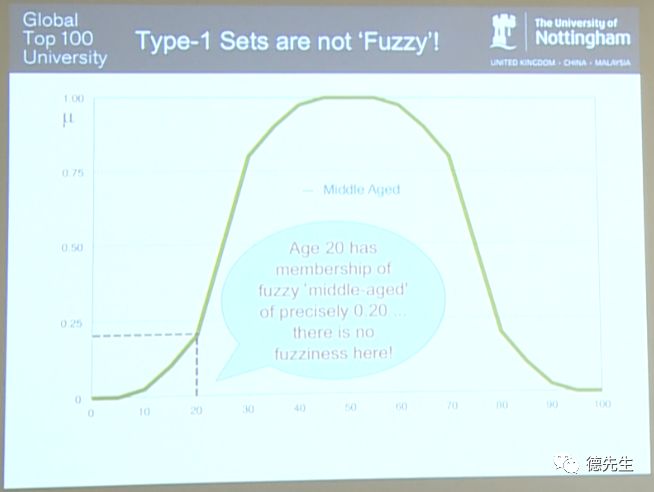
但Type-1数据集在某种意义上来说并不是“模糊”的。例如,若年龄为20岁,则其在如上图所示的模糊集合中属于中年的隶属度(membership)恰好是0.2。而Type-2模糊集合则允许隶属度数值存在一定的模糊性和不确定性。下图所示即为含有不确定区间的Type-2模糊集合。
模糊——Type-2模糊集
Fuzzy--Type-2 Fuzzy Sets
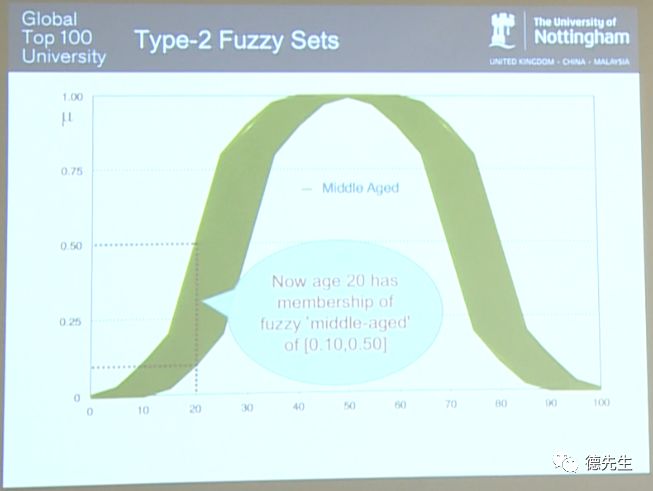
这时,年龄为20岁所对应的隶属度介于0.1到0.5之间,存在一定地不确定性。
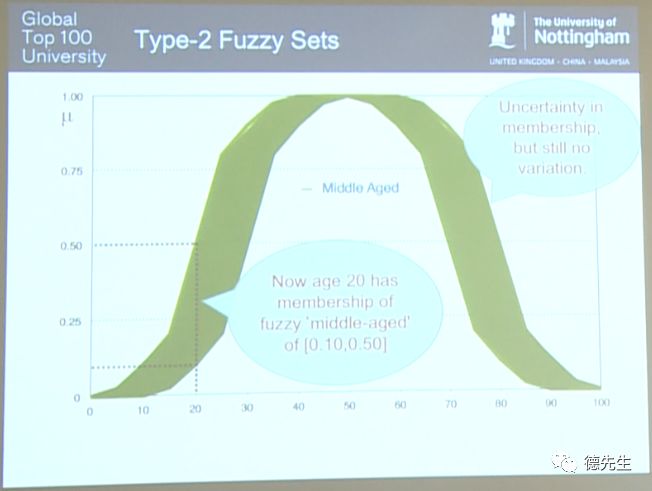
到此为止,虽然Type-2模糊集的隶属度已经具有了不确定性,但还缺少一些变化。
模糊——非平稳模糊集
Fuzzy--Non-Stationary Fuzzy Sets

所以我当时,也就是二十多年前,创建了一种称为非平稳模糊集(Non-Stationary Fuzzy Sets)的新模糊集合。

如上图所示,非平稳模糊集由Type-1模糊集从左向右移动生成。所以每次对其进行查看时,其都可能因小幅度地左右摆动而处于不同的位置,即可得到不同的隶属度数值。
模糊——模糊推理系统
Fuzzy--Fuzzy Inference Systems

一般来说,Type-1推理系统包括数据输入x、运算分析部分和计算所得输出y=f(x)。
模糊——非平稳模糊推理
Fuzzy--Non-Stationary Inference

非平稳模糊系统则由一组Type-1模糊系统组合而成。系统运行一次得到结果y1=f(x, t=1)后,略微移动模糊集合后再次运行系统,则得到与y1略微不同的结果y2=f(x, t=2) 。系统重复运行n次后将得到n个不同计算结果。这里的n可以是任何数字,具体取决于计算机的性能和运算速度。
模糊——集成模糊推理
Fuzzy–Ensemble Fuzzy Inference

随后,实验所得一系列输出结果将进行聚合集成运算(aggregation),即最小值、最大值、平均值、中位数、众数等这类常见数值的求取运算,最后得到新的分析结果yensemble。

需要注意的是,非平稳模糊集不完全算是Type-2模糊集。


系统实验的输出结果分布图展示了不同的集成模糊系统变化(NE Variation,Ensemble System Variation)。
模糊——最佳专家匹配-3%
Fuzzy–Best Expert Match-3%

随后,我们运用非平稳模糊集分别又进行了两个独立的实验来模拟专家变化,实验结果如上。第一个实验对6个临床专家之间分析判定结果的一致性(inter-expert agreement)进行建模分析。结果表明,若将所建立系统的模糊集合在水平方向上的摆动量设定为论域总长度的3%,则可获得最优的专家评定匹配结果。第二个实验对单个专家自身分析判定结果的一致性(intra-expert agreement)进行建模分析,得到与上一个实验结果相同的数值——3%的变化范围。

所以经实验证明,使用非平稳模糊集合能够对专家间和专家内决策的变化均进行合理的模拟建模。但它是否真的有助于决策的制定呢?
模糊——决策制定:乳腺癌治疗
Fuzzy–Decision Making:Breast Cancer Treatment

我曾经进行过很多医疗方面的研究,接下来我将展示另一些来自真实医疗案例的数据结果。这是另一项针对乳腺癌(Breast Cancer)治疗决策问题的医疗研究案例。
模糊——辅助治疗的选择
Fuzzy–Selection of Adjuvant Therapy

我工作所在的诺丁汉大学是乳腺癌医疗的世界级研究中心之一,所以我们的研究团队也非常有幸拥有一些乳腺癌研究领域内世界顶尖的专家学者。
术后治疗(Postoperative Treatment)是一项诺丁汉大学特别的专业医疗技术。这项技术不用于病情诊断,而是已确诊为乳腺癌的女性患者,在通过乳腺中的癌细胞切除手术后,可能所需进行的后续辅助治疗(Adjuvant Therapy),例如化学治疗(chemotherapy)、放射治疗(radiotherapy)等。化学治疗是一种令人非常痛苦的治疗手段,我们希望只在绝对必要的情况下实施化疗。所以我所关注的问题是,能否减少化疗的实施?
模糊——辅助治疗指导
Fuzzy–Adjuvant Therapy Guidelines

在当时,我们只初步进行了是或否的治疗执行决策判断。这是一份乳腺癌临床治疗方案,医生根据肿瘤的大小、癌细胞是否扩散到淋巴结以及肿瘤的大小等级等因素来确定治疗措施,方案中的各类情况所对应的指示变量用于判定是否进行化疗。右下角方框内为最严重的一种癌症的指示变量。其表明,若患者的年龄小于40岁,则建议采取化疗。若年龄大于60岁,则不建议采取化疗。要注意这里的判决条件是一个精确的数字。所以如果你的年龄为39岁,医生会建议进行化疗。而如果你的年龄恰好为40岁,这时该采取哪种治疗呢?对于40岁与60岁之间这段年龄区间,方案中并没有给出具体的治疗指导建议。这时医生可能会让患者自行选择,但患者更倾向于一个是或否的明确答复。所以,我们的目标是建立一个能够模拟对这项治疗方案制定合理且明确决策的模糊专家系统。
模糊——化疗:模糊规则
Fuzzy–Chemotherapy:Fuzzy Rules

我们将临床方案中的规则转化为模糊规则(Fuzzy Rules),具体内容见上图。举例来说,如果指标变量NPI为高(High),ER为非阴性(not Negative)且年龄为年轻(Young),则采取化疗措施。
事实上,我认为清晰易懂的模糊规则是模糊推理一个很大的优势。因为模糊推理规则与临床方案内容是相对应的,这使医生可以快速地做出判断。他们不需要非常了解模糊推理的具体原理,只需要在查看这些规则后进行判定即可。所以“模糊”有时会以某种方式给人以清晰易懂的印象。
模糊——模糊意见的一致性
Fuzzy–Fuzzy Group Agreement
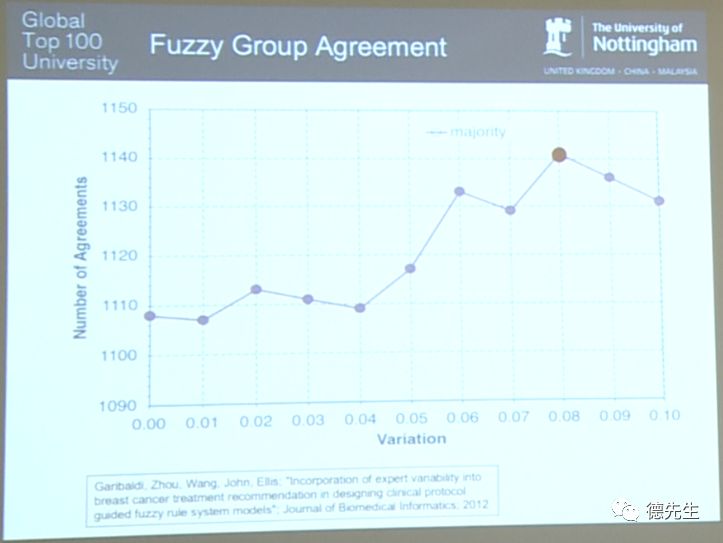
接下来我将直接切入实验的结果部分。X轴的数值代表模糊集合在X轴方向上的一系列摆动变化量,例如0.01即模糊集合具有1%的不一致论域。0.00则表示没有变化,即Type-1模糊系统。Y轴的数值代表系统判定与临床实验所得一致结果的数量。我们想要建立一个能够获得与专家分析所得结果相一致的系统,虽然不能做到全部完全一致,但希望使相同结果的数量尽可能地提高,也就是将Y轴上的数字最大化。
我们首先建立了Type-1模糊专家系统,对系统进行优化后得到Y轴上交点所对应的最佳优化结果,随后由非平稳系统实验得到上图中其他数据结果。对于每一个不同的变化量,我们都将其重复构建30次并获得30个不同的结果,取出其中占多数的结果作为最终唯一的集成结果。实验表明,当变化量取值为8%时,即在X轴方向取8%摆动量的情况下,一致结果的数量达到了最大,数值约为1140。结果证明,非平稳模糊集合的应用能够使系统的性能得到进一步提升。

所以说,结合集成决策方法的非平稳模糊集合可以提升决策的质量。
后来我们也进行了很多其他的相关研究工作,但由于前面讲解和讨论花费了太长时间,所以我直接进入讲座的总结部分。
总结
Summary

Type-2模糊系统为模拟人类推理过程提供了非常丰富的背景环境。但我们目前的研究主要针对非平稳和Type-2的关系,针对那些既不是Type-1也不是Type-2的模糊系统。同时,我认为Type-2模糊系统的相关研究仍存在很大的空间。Type-1模糊系统的研究至今已经持续了将近50年,我认为其在很多方面的研究已经相当成熟。虽然目前我们仍会接收到很多针对Type-1模糊系统研究的论文投稿,但老实说,或许作为期刊主编我不应该这么说,我对这些文章的内容并不是那么感兴趣。对我来说,Type-2模糊系统的研究工作更有价值,因为这个领域内还有很多非常值得研究的开放性问题,以及关于建模和推理方面有意义的研究应用。

最后,如果你们想要发表关于模糊理论的相关研究成果,欢迎向IEEE Transaction on Fuzzy Systems投稿。
王飞跃教授:
我认为接下来的研究方向是将Type-2模糊系统应用于智能决策和智能信息处理。除此之外,还应该进一步推动自然语言处理的相关研究,因为人类语言也是模糊的。虽然目前可以使用深度学习成功地实现NLP(Natural Language Processing),但实际上,深度学习在某种意义上可以说是由模糊理论发展而来的。你应该推动这个方向的研究,特别是针对Type-2模糊系统的非生产相关的研究。
主讲嘉宾:
我非常同意你的看法,这也可以说是我来这里进行本次讲座的原因。在这里我还想再次简要的阐述一下非平稳模糊集合,因为这是一个非常有意思的研究内容。

这是非平稳模糊集合的示意图。我的问题是,一个静态的Type-1模糊系统该如何进行学习?
学习是什么?学习就是为系统提供激励并获得反馈的过程。如果系统对每次激励都给出相同的反馈,那这就不算是学习,因为系统会慢慢适应已有数据。而学习需要做的是,在某一时刻能够对激励给出不同的反馈,所以系统需要进行一些随机的变化。如果对反馈进行一些变化调整,若变化有效则进一步调整和完善系统,这就达到了学习的目的。所以做出改变是为了更好的学习,没有变化是不能够进行有效学习的。而针对自学习模糊系统(Learning Fuzzy System)这方面的研究非常之少。
通常来说,自学习模糊系统构建完成之后不是保持静态固定的。事实上,我们获得的应该是能够不断进化的系统。这意味着应该利用持续革新的技术去处理和分析数据,并不断地对模糊系统进行调整和完善,使其在搭建完成后具有动态调整的特性。
王飞跃教授:
目前我们正在进行一个类似的研究项目,我们不仅使隶属度对应数值发生改变,同时也改变论域的范围。
我想问一下,Type-2模糊专家系统投入实际使用了吗?还是仍处于实验研究状态?
主讲嘉宾:
就像我说的,这项研究工作最早可以追溯到20年前。
王飞跃教授:
那么他们目前还仍然在使用吗?据我所知,大部分专家系统都已经消失了。
主讲嘉宾:
是的,但我的回答是我不知道。在1999年和2000年,医院还在使用模糊专家系统。
王飞跃教授:
绝大多数专家系统都已经消失了,我认为现在应该重新开展相关研究。我希望能够进一步和你探讨这个问题。
主讲嘉宾:
说到这,我想对正在攻读博士的学生提出一个建议。在刚刚过去的一个小时之内我所讲解的内容涵盖了超过20年的研究工作。也就是说,我研究模糊专家系统的时间已经超过20年了,但我认为现在一些新颖的想法和技术使这个研究问题变得更加有趣。所以我的建议是,在选择确定自己的研究领域后,要坚定自己认为对的想法并坚持和专注地进行相关研究工作。要知道我在1999年研究模糊专家系统的时候,人们都认为这项工作没有任何意义。
王飞跃教授:
我认为这项研究今后会变得越来越重要。我希望下个月能够再次会面,并针对这个问题进行进一步探讨。
Q&A

提问:如果想要建立一个具有动态隶属度和论域的系统,那么怎样在改变隶属度的情况下同时实现对论域也进行变化?
回答:与我所举年龄的示例相比,这显然是另一种情况。我用年龄进行举例是因为,如果在课堂上对学生提问,你们认为中年人的平均年龄是多少?通常会得到30个不同的答案。当然在这种情况下,论域已知并且固定。我曾经发表过关于论域变化相关研究的论文,在其中将其称为环境依赖的(context dependent)论域,也就是说论域的范围是依赖环境而发生改变的。所以我认为论域是动态的同时它也是静态的。对于不同的情况,这两种状态都是适用的。
https://blog.sciencenet.cn/blog-2374-1120234.html
上一篇:平行驾驶与平行交通:未来出行新思路
下一篇:生成式对抗网络:从生成数据到创造智能