博文
为什么机器学习/数据科学的数据探索中要进行数据可视化?
||
不要说数据可视化的优点,以及为了展示给老板看。
本文参考维基百科:https://en.m.wikipedia.org/wiki/Anscombe%27s_quartet
下图是著名的安斯库母四重奏,
它们具有相同的统计值,但不同的x,y,然而结果用简单的线性回归建模却得到同样的结果,事实上,拟合的结果的准确性是值得商榷的,有的效果可以,有的却是错误的。
Property | Value | Accuracy |
Mean of x | 9 | exact |
Sample variance of x 样本方差 | 11 | exact |
Mean of y | 7.50 | to 2 decimal places |
Sample variance of y | 4.125 | plus/minus 0.003 |
Correlation between x and y | 0.816 | to 3 decimal places |
Linear regression line | y = 3.00 + 0.500x | to 2 and 3 decimal places, respectively |
Coefficient of determination of the linear regression 线性回归的确定系数 | 0.67 | to 2 decimal places |
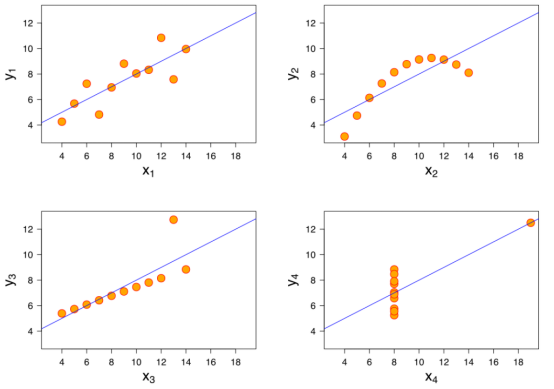
好好看看,第二个图和第四个图是不是直接错误,第三个图勉强算对,但不准确,有个离群值明显可以舍去。第一个图是正确的。
由此可见,在数据探索中,有必要进行简单的验证,查看数据是否可以用已有的模型,模型重要,但数据质量更重要。
https://blog.sciencenet.cn/blog-1966190-1116766.html
上一篇:数据到底有什么卵用?
下一篇:为什么说python是氢弹?