博文
也谈谷歌用数据进行流感预测的意义?
|||
下面的消息来自曲江文的研究,题目是用数据进行流感预测为什么失败?
尽管此文在于批评谷歌数据使用中的问题,但是让我看到,即使谷歌这次预测的算法失效了,但是提出来一个这么好的思路,其功不可没,这种算法不断改进,最后还是可以得到惊人成功的。
这种思路不仅可以用来预测疾病,也可以用来预测一些基层政府的不合理政策,比如强迫拆迁,贪污受贿,以及扶贫款不到位等问题。甚至可以发现罪犯制造冰毒,武器或者炸药的痕迹。在国家斗争层面上,如果一个国家某个行业检索原子核空天飞行器,超燃发动机,或者基因重组病毒培养的数据量突然提高,那么说明什么?也是很清楚的。这种数据挖掘,不仅卫生部门可以用,政府部门可以用,警察可以用,军事情报部门用它更是不可多得的帮手。
下面是批评者认为谷歌流感趋势计算的不准确的一个图。GFT预测显示某次的流感爆发非常严重,然而疾控中心(CDC)在汇总各地数据以后,发现谷歌的预测结果比实际情况要夸大了几乎一倍,如下图所示,然而你仔细看这个图,几条曲线从趋势上还是十分一致的,能计算到这种程度应当说是不错了。
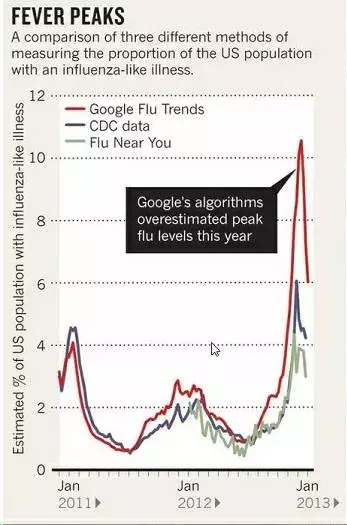
下面是引用的原文,我这里仅仅抛砖引玉,说明谷歌大数据用好了,信息是个宝藏,如果百度也能用也就好了,可惜啊,我国的百度以广告谋生,你要什么没什么。
下面是原文
______________________________________________________________________________________________________
2009年2月,谷歌公司的工程师们在国际著名学术期刊《自然》上发表了一篇非常有意思的论文:《利用搜索引擎查询数据检测禽流感流行趋势》,并设计了大名鼎鼎的流感预测系统(Google Flu Trends,GFT,访问网址为:www.google.org/flutrends/)。
GFT预测H1N1流感的原理非常朴素:如果在某一个区域某一个时间段,有大量的有关流感的搜索指令,那么,就可能存在一种潜在的关联:在这个地区,就有很大可能性存在对应的流感人群,相关部门就值得发布流感预警信息。
GFT监测并预测流感趋势的过程仅需一天,有时甚至可缩短至数个小时。相比而言,美国疾病控制与预防中心(Center for Disease Control and Prevention,CDC)同样也能利用采集来的流感数据,发布预警信息。但CDC的流感预测结果,通常需要滞后两周左右才能得以发布。但对于一种飞速传播的疾病(如禽流感等),疫情预警滞后发布,后果可能是致命的。
GFT一度被认为是大数据预测未来的经典案例,给很多人打开了一扇未来的窗口。根据这个故事,大数据的布道者们给出了4个令自己满意的结论:
1)由于所有数据点都被捕捉到,故传统的抽样统计的方法完全可以被淘汰。换句话说,做到了“n=All”;
2)无需再寻找现象背后的原因,只需要知道某两者之间的统计相关性就够用了。针对这个案例,只需知道“大量有关流感的搜索指令”和“流感疫情”之间存在相关性就够了。
3)不再需要统计学模型,只要有大量的数据就能完成分析目的,印证了《连线》主编Chris Anderson 提出的“理论终结”的论调。
4)大数据分析可得到惊人准确的结果。GFT的预测结果和CDC公布的真实结果相关度高达96%。
但据英国《财经时报》(FT)援引剑桥大学教授David Spiegelhalter毫不客气的评价说 ,这四条 “完全是胡说八道(complete bollocks. Absolute nonsense)”。
针对前3条观点的不足之处,前文故事已经涉及到了,不再赘言。针对第4条,我们有必要再解析一下——GFT预测是如何失效的?
谷歌工程师们开发的GFT,可谓轰动一时,但好景不长,相关论文发表4年后,2013年2月13日,《自然》发文指出,在最近(2012年12月)的一次流感爆发中谷歌流感趋势不起作用了。GFT预测显示某次的流感爆发非常严重,然而疾控中心(CDC)在汇总各地数据以后,发现谷歌的预测结果比实际情况要夸大了几乎一倍,如图所示。
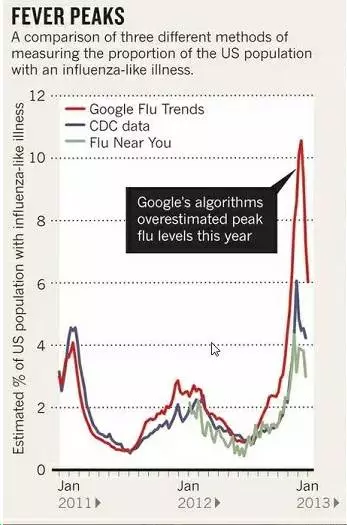
研究人员发现,问题的根源在于,谷歌工程师并不知道搜索关键词和流感传播之间到底有什么关联,也没有试图去搞清楚关联背后的原因,只是在数据中找到了一些统计特征——相关性。这种做法在大数据分析中很常见。为了提高GFT的预测准确性,谷歌工程师们不断地微调预测算法,但GFT每一次算法微调,都是为了修补之前的测不准,但每次修补又都造成了另外的误差。
谷歌疫情之所以会误报,还因为大数据分析中存在“预测即干涉”的问题。量子物理创始人之一维尔纳·海森堡(Werner Heisenberg),曾在1927年的一篇论文中指出,在量子世界中,测量粒子位置,必然会影响粒子的速度,即存在“测不准原理”。也就是说,在量子尺度的微距世界中,“测量即干涉”。如今,在媒体热炒的“大数据”世界中,类似于“测不准原理”,即存在“预测即干涉”悖论。
这个“预测即干涉”悖论和“菜农种菜”的现象有“曲艺同工”之处:当年的大白菜卖价不错(历史数据),预计明年的卖价也不错(预测),于是众多菜农在这个预测的指导下,第二年都去种大白菜(采取行动),结果是,菜多价贱伤农(预测失败)。
进一步分析就可发现,GFT预测失准在很大程度上是因为,一旦GFT提到了有疫情,立刻会有媒体报道,就会引发更多相关信息搜索,反过来强化了GFT对疫情的判定。这样下去,算法无论怎么修补,都无法改变其愈发不准确的命运。
对GFT预测更猛烈的攻击,来自著名期刊《科学》。2014年3月,该杂志发表由哈佛大学、美国东北大学的几位学者联合撰写的论文“谷歌流感的寓言:大数据分析中的陷阱(The parable of Google Flu: traps in big data analysis)”,他们对谷歌疫情预测不准的问题做了更为深入地调查,也讨论了大数据的“陷阱”本质。《科学》一文作者认为:大数据的分析是很复杂的,但由于大数据的收集过程,很难保证有像传统“小数据”那样缜密,难免会出现失准的情况,作者以谷歌流感趋势失准为例,指出“大数据傲慢(Big Data Hubris)”是问题的根源。
《科学》一文还认为,“大数据傲慢(Big Data Hubris)”还体现在,存在一种错误的思维方式,即误认为大数据模式分析出的“统计学相关性”,可以直接取代事物之间真实的因果和联系,从而过度应用这种技术。这就对那些过度推崇“要相关,不要因果”人群,提出了很及时的警告。毕竟,在某个时间很多人搜索“流感”,不一定代表流感真的暴发,完成有可能只是上映了一场关于流感的电影或流行了一个有关流感的段子。
果壳网有一篇对《科学》一文深度解读的文章:“数据并非越大越好:谷歌流感趋势错在哪儿了?”,感兴趣的读者可以前去围观。
https://blog.sciencenet.cn/blog-1354893-1246624.html
上一篇:向搞岩石断裂力学的专家紧急求助!
下一篇:北斗短报文求助最有效的压缩方式,以便应用在油田,矿山,海洋探测管理通讯等领域