博文
一个解析SOOPAT专利信息并追加到NoteExpress的小工具(开源)
|||
NoteExpress是一个不错的国产文献数据库,前几年我研究过它的接口使用,可以利用它的接口进入导入和导出数据,只是官方没有公开具体的使用说明,只好自己摸索。好在类型库中的名称比较规范,还多少可以猜测一些出来,因此还可以玩玩. 因为本人比较喜欢读专利,看到感兴趣的专利信息就在NoteExpress数据库中保存起来。前些年我经常在国家知识产权局官方网站上看,那时网站速度还比较快,现在辄是动不动就跳出“流量太大”要识别数字认证,烦不胜烦,所以就改用Soopat了,虽然要付费,但体验相当好.
为了保存一些专利的信息,如申请号,申请时间,名称,申请人等,最早的时候我很勤奋,手工输入,在NE中新建一个题录(就是一条记录)再一个字段一个字段的手工输入,虽然打字很快,但速度还是慢,特别是要在NE中一个个字段切换来切换去,相当的麻烦。
后来就想了个办法,用Delphi写了个文本处理工具,只要选中网页内容一拖到界面上就自动将内容复制到文本控件,再解析文本的内容找出各项信息,保存到INI文件中。这样就非常快的将要输入的专利相关信息解析好了。然后摸索了很久, 边学边尝试,写了一个集成到资源管理器的DLL服务器,在选择相应的INI文件后,点击弹出菜单的设定项,调用NE的接口将文本内容按字段一项项导入到NE中。就这样玩了几年,积累了6000多条感兴趣的专利信息记录。
没想到2015年我在用硬盘对拷的工具备份时,由于硬件的问题,将我的硬盘损坏了两个大分区,损坏了大量的数据,生生的把这些非常宝贵的资料弄没了(在京东网买的,投诉无人理睬,自从之后,我再也不买这家(ORICO)的硬件,再也不用京东的账号)。
后来,由于国家知识产权局的网站改版,网页格式变了,我的浏览器也不再用maxthon而是改成了Chrome,这个工具也不好用了。由于学艺不精,用Delhpi写这些东西太累,慢慢的这套工具不用了。
在接触正则表达式之后,发现这个玩意正好是解析文本的好帮手,用来处理专利信息非常适合,而OFFICE中正好有正则的引擎,于是想用WORD的VBA来做个解析工具看看,这个小工具就这么诞生了。
思路:从网页复制文本,在工具中粘贴,粘贴后利用正则表达式解析文本,得到各种信息放到文本框,再利用NoteExpress的接口将这些分解好的信息导入到NE中生成题录。
详细的我就不讲了。如果你觉得有用,请Email 告诉我一声就够了,谢谢。
不过,如果你的OFFICE没有启用宏,这个工具是无法运行的。宏是很强大的工具,非常有用,不能因为曾经出现过宏病毒就谈虎色变,我特意开源了,有兴趣你可以自己看看代码是否安全。
放两张相关的图如下,界面左下角 两个文本框供用户分别输入关键词和注释,关键词用空格分开即开,保存时会自动将空格替换成分号以适应NE的要求。
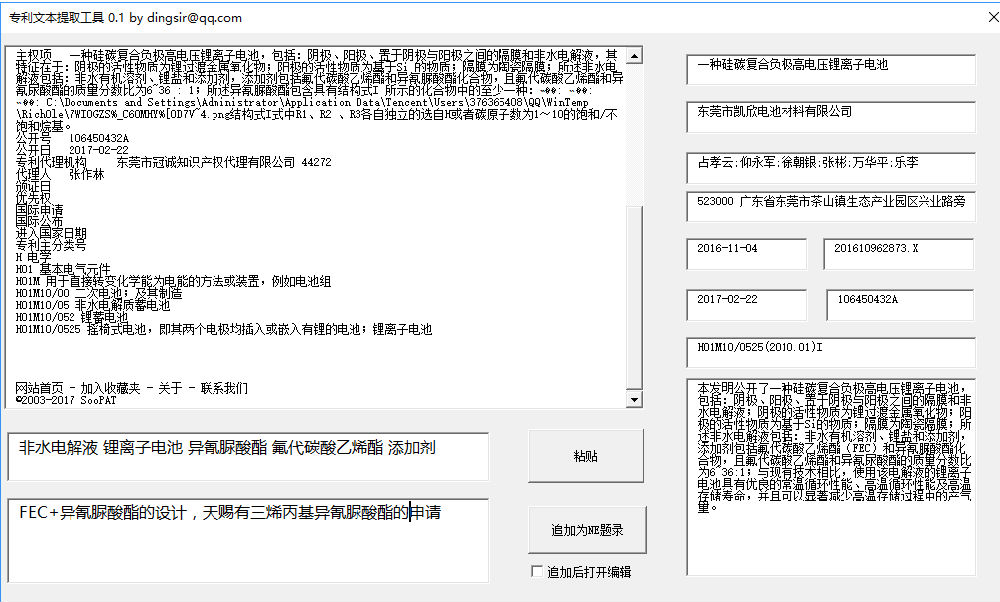

因为我的电脑是64位Win10 + 64位OFFICE2016, 其它版本我没测试,有问题请Email
https://blog.sciencenet.cn/blog-1213210-1058983.html
上一篇:漫谈化学结构的文本表示法 SMILES, CAL脚本以及用CAL生成SMILES
下一篇:工作表和VBA环境中ASC函数的差异(同名不同动作)