博文
漫谈化学结构的文本表示法 SMILES, CAL脚本以及用CAL生成SMILES
|||
我有一个自建的化学数据库,用于收集一些锂电物质的资料,比如熔点、沸点、介电常数、闪点、缩写以及分子结构等信息.我经常在阅读专利时看到一些有意思的化合物或添加剂,就把它们的信息收集整理整理放到这个数据库中,时间长了居然也有几百种物质了。这个数据库是用ChemFinder(简称CF)构建的,作为ChemOffice中一员,CF与另两个成员ChemDraw和Chem3D相比,它太不出名了,网上能找到的资料极少,想发掘一下它的功能也是困难重重.找人求助都不知道哪里去.
化学结构用字符串来表示的方法:SMILES
从平时的使用中,我发现化学结构式需要用专业软件来描绘具有相当的局限性, 能不能将结构转化为文本来使用呢? 我偶尔发现,这种解决方法确实是有的,前人已经想过这个问题了,有几种解决方案,其中比较容易理解的一种表示方式就是SMILES. 引用百度百科上的一段描述如下
SMILES(Simplified molecular input line entry specification),简化分子线性输入规范,是一种用ASCII字符串明确描述分子结构的规范。SMILES由Arthur Weininger和David Weininger于20世纪80年代晚期开发,并由其他人,尤其是日光化学信息系统有限公司(Daylight Chemical Information Systems Inc.),修改和扩展。由于SMILES用一串字符来描述一个三维化学结构,它必然要将化学结构转化成一个生成树,此系统采用纵向优先遍历树算法。转化时,先要去掉氢,还要把环打开。表示时,被拆掉的键端的原子要用数字标记,支链写在小括号里。
SMILES字符串可以被大多数分子编辑软件导入并转换成二维图形或分子的三维模型。转换成二维图形可以使用Helson的“结构图生成算法”(Structure Diagram Generation algorithms)。
先讲一下怎么生成和转化SMILES,以ChemDraw为例 :
在ChemDraw里面,先绘制一个分子,然后选中,点击点击 Edit-Copy As-SMILES就可以将结构式转化为字串并复制到剪贴板上. 需要的时候,在ChemDraw的右键菜单中依次点击 Paste Special -- SMILES就可以将剪贴板上的SMILES字串转化为结构式粘贴到ChemDraw中. 如果普通的粘贴,则得到SMILES字串而不出转换后的结构式.
有了SMILES,最大的好处是,我们可以将化学结构存储到一个普通的文本文件或文本型字段中,如TXT文件,CSV文件或EXCEL的某个单元格中,这样以后再利用时,粘贴到化学软件中就可以转化为可视化的结构式.这种中介形式对文献数据库来说挺有用的--以前我在自用的NoteExpress文献数据库中就专门设计了一个文本型的字段来存储SMILES,要用这个结构时,只需要把SMILES复制出来放到化学软件中,它就恢复原形了. 另外,如果你需要传递一个化学结构式给另一人,手头正好没有化学绘图软件的话,只要会转化SMILES,把它转换成SMILES字串用QQ/微信甚至短信都可以传给对方. 也有一些化学网站支持用SMILES搜索,如www.chemexper.com就可以输入SMILES搜索化学物质.
先举个简单的例子来理解一下,将分子结构转化为SMILES.
乙烷→ CC 丙烷→ CCC 乙烯→C=C 乙炔→C#C
乙腈→ CC#N 醋酸→CC(=O)O 乙酸乙酯→CC(=O)OCC
看出来了没有,有这么几个特点
1)省略了氢,单键不必表示相邻即可,双键用=,叁键用#表示
2)以一条链的思路来分解, 侧链放在小括号内,紧跟在相连的原子后.
那么带环的怎么弄呢? 拆开时在拆开的地方做上数字标记就好了.
环已烷 → C1CCCCC1
两个标记为1的原子(即两个C1)是连在一起的.这样就可以把环还原出来了. 两个数字1,第1个用于标识起点的原子,第2个用于标识绕回来的最后一个原子.
如果是甲基环已烷呢? 可以有两种不同的解法,方法1从甲基开始经过环的一侧回绕到成环的碳上,可以得到这样的SMILES:
CC1CCCCC1
方法2是从将甲基视为侧链,从甲基伸出的那个碳开始分解,可以得到
C1(C)CCCCC1
这两种都是可以正常识别的. 支链解析串记得紧跟在分支的原子后面,用小括号括起来.同样的,你可以选择其它的碳原子作为起点来解析,得到的SMILES不一样,但都是有效的.但是,不管怎么解析,写出来的各类非氢原子数都是一样多的.
现在来一个相当复杂的结构,即LIBOB的SMILES. 先补充说两个规则
1)离子的表示,在原子后面放上正负数字,用中括号括起来.
2)由于正负离子之间没有共价键,用点号分隔开
对LIBOB, 我设计的分解方法见下图, 第一条链的描述视为主链,不加括号,按红色箭头指引的路线解析.
从草酸根的羰基氧开始编号, 碰到的第1个碳有两个非氢原子连接,要拆开,标记为1 ,后面碰到的B又有多个非氢原子连接, 标记为2.所得到的描述是OC1O[B-]2OC1=O。
由于硼原子上还有一个环,视为支链,按蓝色箭头解析为OC(=O)C(=O)O2,把它放在括号内,要插到硼原子后面
于是得到OC1O[B-]2(OC(=O)C(=O)O2)OC1=O.[Li+]
现在复制这个字符串,再到ChemDraw中Paste Special -- SMILES就看到结果了.

不过,如果你再选择这个结构,Copy As -SMILES 再粘贴文本,可以看到软件生成的并不是这样的,呵呵,它走的路径不同而已.
再举一个例子,以超电容里面的一种新型电解质SBP为例子吧,它是一种螺环季铵盐,结构与解析结果如下:
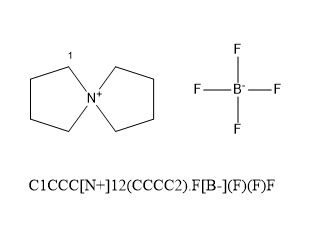
稍有不同的是,这次解析N原子在第1条链上同时编了1和2号, 第1条链中与C1相接编上了1,但右边环视为侧链时,最后一个原子连接到N上,N原子必须标为2才行.所以N与最后那个C都编号为2. 具体的你可以玩味一下.必须保证闭合环的首尾原子的标记数字相同. (此外,如果支链返回到成环的节点时不是单键而是双键或叁键,应该写成C=1或C#1这样的形式以表示通过双键或叁键接回来的)
有兴趣更进一步阅读的,可以看看SMILES的规范,我这里翻译了一个维基百科的介绍页,补充了不少内容,见附件. ![]() 维基百科的SMILES词条.docx
维基百科的SMILES词条.docx
如果要非常详细的规范,这里有权威的解释. Daylight Chemical 的 SMILES的规范
ChemFinder的CAL脚本语法
SMILES这么有用,但是ChemFinder始终没有提供一个自动生成SMILES的控件,它提供的计算功能有分子量,分子式,但是没有SMILES, 如果要存储SMILES,就得自己手动将结构式在ChemDraw里复制为SMILES再粘贴到CF窗体的对应字段中来.每次都这样操作是比较繁琐的,这样重复性的工作最好是让软件自动来做.但没有找到自动化的方法之前,要么不存储,要么手工来解决,两种选择都不理想. 我以前也尝试过用PYTHON来解析结构生成SMILES(ChemOffice提供了ChemScript脚本,基于Python语言),但由于ChemScript模块一直不正常,这个方向就NG了.
这几天在研究CF的窗体功能时,发现它提供了少数几个事件的外挂脚本处理的功能,支持运行两种脚本,即CAL脚本和PYTHON脚本. 我就在想,CAL 或许还可以试试.
我知道CAL脚本在界面的Scripts菜单下面也有两个例子, 和一些帮助提示.但比较简单,不知道怎么用.上网搜索一遍也没有什么收获(可见CF多么冷门).最后想想只有查CF自己的帮助了.果然有不少内容讲解CAL语法,虽然是英文的,只要有耐心也不算太困难,慢慢看吧.
CAL就是ChemFinder Automation Language的缩写,也就是CF自动化语言的意思.看得出来这玩意是专门给CF自己用的.这个语法与其它脚本语言相比不大一样,而且功能弱了太多.最可气的是,帮助文件中很多代码的换行/空格都没有,甚至有时代码复制出来修正错误以后都还不能运行,这可是我见过做得最粗糙的帮助!(就CAL语言这一部分做得非常差,其它部分还可以).
连蒙带猜,结合极为有限的几个例子,我还是明白了一点点.
CAL脚本有两种保存方式,一种存为独立的CFS文件,另一种保存是窗体中.搜索一下软件自带的browse.cfs或zoom.cfs文件,将你的脚本保存到相同的路径下就会被CF自动加载,显示在Scripts菜单下面,点击相应的菜单即可以运行。
先说下努力的结果: 在CF数据库的界面上,点击设计模式,进入设计状态,在窗体的空白处点右键,选择Properties, 进入Form标签,如图,勾选Commit Changes, 再点击Edit...

跳出来脚本编辑窗体,在左边点选CAL,右边框内输入代码,最终结果如图:
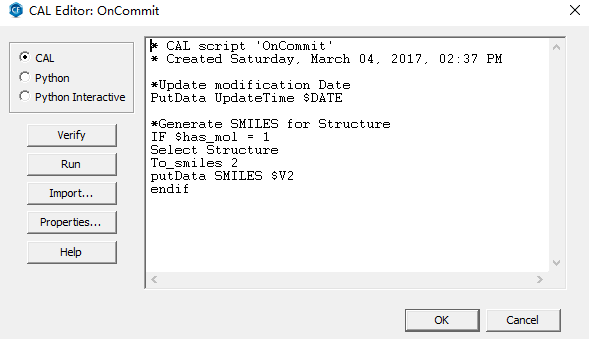
对上述脚本的作用讲解一下: 这点脚本是写在Commit Changes事件处理代码中(也就是保存修改的数据时发生的事件),在保存数据时被调用, 会自动更新UpdateTime字段,并且将当前结构的SMILES保存到名叫SMILES的字段中,省去了自己从ChemDraw中复制再到CF中粘贴的烦恼.
CAL脚本里面,首字符是*开头的行为注释行
* CAL script 'OnCommit'
* Created Saturday, March 04, 2017, 02:37 PM
*以下的$DATE, \$HAS_MOL为CF的环境变量,由CF自已更新.
*PutData命令将\$DATE代表的日期(今天) 存储到UpdateTime字段, 记下修订数据的时间
PutData UpdateTime \$DATE
*Generate SMILES for Structure
* 如果$has_mol 变量 为 1(表示当前记录中有结构式).注意变量,等号, 1之间要有空格分开,不能写在一起
IF \$has_mol = 1
*选择对象框, Structure是结构存放的控件的名字
Select Structure
*将结构转化为SMILES, 存储到变量2. 这种变量表示法真是古怪.
*CF提供了9个变量,要使用变量用\$V1,\$V2,$V9等来表示.这些变量似乎是没有类型的通用变量.
*TO_SMILES是CF提供的内部命令,将当前结构转化为SMILES字串
To_smiles 2
*将变量2(用$V2来引用)的内容存储到SMILES字段.注意这个SMILES是我设计的文本框的名字,也是数据库的字段名.
putData SMILES $V2
*判断结束,注意END 与IF之间没有空格分开,是连在一起的.
endif
根据我粗浅的理解, CAL的基本框架是:
1.提供了一批内置的命令
如菜单命令 File Save, File Close, Query Find; 需要帮助你可以直接在脚本行中运行help就可以调出来. 对于命令不一定要写出全文,只要足够字符不会导致歧义就行.如Record next record, 输入rec n 就够用了. 但可用的有哪些菜单命令,CF的帮助没有提供清晰的列表.
如变量处理命令 GetData, PutData, SetVal, AppendVal, ReadVal, WriteVal 等;
判断与控制语句 如 IF, Else, Endif, Loop, Exit, Endloop,Goto;
交互的命令如Input, Msg, Password, DDE, EXEC, DOS, EXEC_BUTTON,Launch, output_str 等
数据库处理的命令如OpenDB,CreTable, DelTable,SelTable, CreField, DelField, Sort;
创建控件的命令如Text,Frame, Pict, Button, SubFm, ArrowBox,FrameDBox等
数据处理的命令,如From_smiles, to_smiles, clean 等.
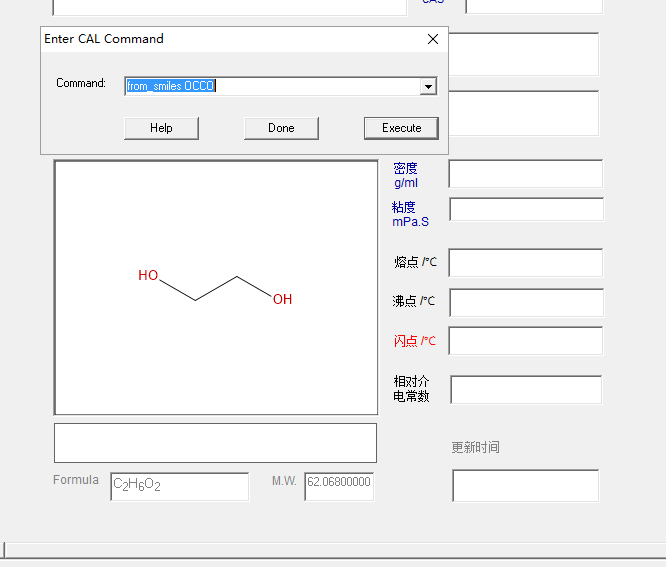
比如,你打开了一个CF数据库,想新增加记录后,输入一个新的结构如乙二醇,又不想启动ChemDraw来画,你可以点击菜单栏的Scripts 再点击command line, 弹出脚本运行框,输入from_smiles OCCO,再点击一下Execute就可以看到, 结构式的框中自动出现了乙二醇的结构式. 如果你觉得结构框里面的结构式画得不漂亮,想利用ChemDraw的Clean up功能整理一下,在脚本运行的界面上输入clean再执行就可以做到了. 是不是很方便?
2.提供了一批内部环境变量,如\$ID(当前的MOL_ID, 这个是CF数据库必备的字段), \$RECNO(记录序号), \$HAS_MOL(当前记录中是否有结构), \$HAS_DATA(选中控件中是否有数据), \$DATE(今天日期), \$CLIPBOARD(剪贴板文本), $BOX_EXISTS(判断数据控件是否存在),
3)1和2配合着来处理自动化的需求.
相比于VBA,Python等,CAL只提供非常简单的语法和操作能力. 没有调试监控等功能. CAL引擎中的BUG也比较多,例如Password语句如果点取消则可以退出程序导致密码监控失效. 有时简单的语句也不能正常的运行等等.
CAL脚本的应用示例
尽管是这样,如果用得好,CAL脚本还是能够帮你一点忙的.以下是我写的几个脚本,供喜欢的朋友参考.脚本保存的路径见上面交代的路径.
*查找Chinese字段
*Msg 请输入中文名的片段
Input 1 Please Input Chinese name here
if $v1 = "" exit
append off
search enter query
putdata ChineseName $v1
search find
search retrieve all
-----------------------------
*将结构转化为SMILES
IF $has_mol
Select Structure
To_smiles 2
putData SMILES $V2
endif
-------------------------------
*搜索 含有 空白 二字的记录,因为有中文,保存的CFS文件要用ASCII编码保存,否则乱码.
append off
search enter query
putdata ChineseName 空白
search find
search retrieve all
----------------------------------------
*将数据库记录中的结构单独存为文件,以序号为文件名,保存目录为C:\temp\
loop
setval 1 c:\temp\
appendval 1 $index
appendval 1 .cdx
writemol $v1
pause 10
record next
endloop
是为记. 2017.8.29 更新标题和小修改.
2018-4-20 修改倒数第二个语句块
2018-7-7 提供三个CFS脚本.![]() My CFS files.rar
My CFS files.rar
https://blog.sciencenet.cn/blog-1213210-1037507.html
上一篇:心算任意年份的天干地支的方法
下一篇:一个解析SOOPAT专利信息并追加到NoteExpress的小工具(开源)