博文
[转载]Delaunay三角剖分 及算法 基本知识
|||
摘自百度百科 http://baike.baidu.com/view/1691145.html?tp=2_11
http://www.geomodel.net/article/code/20080601/7510.html
1. 三角剖分与Delaunay剖分的定义
如何把一个散点集合剖分成不均匀的三角形网格,这就是散点集的三角剖分问题,散点集的三角剖分,对数值分析以及图形学来说,都是极为重要的一项预处理技术。该问题图示如下:
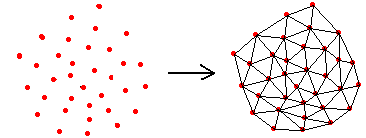
1.1.三角剖分定义
【定义】三角剖分:假设V是二维实数域上的有限点集,边e是由点集中的点作为端点构成的封闭线段, E为e的集合。那么该点集V的一个三角剖分T=(V,E)是一个平面图G,该平面图满足条件:
1.除了端点,平面图中的边不包含点集中的任何点。
2.没有相交边。
3.平面图中所有的面都是三角面,且所有三角面的合集是散点集V的凸包。
1.2. Delaunay三角剖分的定义
在实际中运用的最多的三角剖分是Delaunay三角剖分,它是一种特殊的三角剖分。先从Delaunay边说起:
【定义】Delaunay边:假设E中的一条边e(两个端点为a,b),e若满足下列条件,则称之为Delaunay边:存在一个圆经过a,b两点,圆内(注意是圆内,圆上最多三点共圆)不含点集V中任何其他的点,这一特性又称空圆特性。
【定义】Delaunay三角剖分:如果点集V的一个三角剖分T只包含Delaunay边,那么该三角剖分称为Delaunay三角剖分。
1.3.Delaunay三角剖分的准则
要满足Delaunay三角剖分的定义,必须符合两个重要的准则:
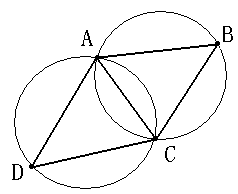
1、空圆特性:Delaunay三角网是唯一的(任意四点不能共圆),在Delaunay三角形网中任一三角形的外接圆范围内不会有其它点存在。如下图所示:
1.最接近:以最近临的三点形成三角形,且各线段(三角形的边)皆不相交。
2.唯一性:不论从区域何处开始构建,最终都将得到一致的结果。
3.最优性:任意两个相邻三角形形成的凸四边形的对角线如果可以互换的话,那么两个三角形六个内角中最小的角度不会变大。
4.最规则:如果将三角网中的每个三角形的最小角进行升序排列,则Delaunay三角网的排列得到的数值最大。
5.区域性:新增、删除、移动某一个顶点时只会影响临近的三角形。
6.具有凸多边形的外壳:三角网最外层的边界形成一个凸多边形的外壳。
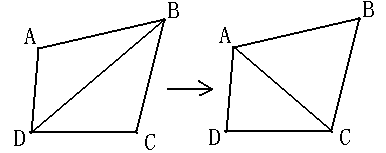
1.5.局部最优化处理
理论上为了构造Delaunay三角网,Lawson提出的局部优化过程LOP(Local Optimization Procedure),一般三角网经过LOP处理,即可确保成为Delaunay三角网,其基本做法如下所示:
1.将两个具有共同边的三角形合成一个多边形。
2.以最大空圆准则作检查,看其第四个顶点是否在三角形的外接圆之内。
3.如果在,修正对角线即将对角线对调,即完成局部优化过程的处理。
LOP处理过程如下图所示:
2.Delaunay剖分的算法
Delaunay剖分是一种三角剖分的标准,实现它有多种算法。
2.1.Lawson算法
逐点插入的Lawson算法是Lawson在1977年提出的,该算法思路简单,易于编程实现。基本原理为:首先建立一个大的三角形或多边形,把 所有数据点包围起来,向其中插入一点,该点与包含它的三角形三个顶点相连,形成三个新的三角形,然后逐个对它们进行空外接圆检测,同时用Lawson设计 的局部优化过程LOP进行优化,即通过交换对角线的方法来保证所形成的三角网为Delaunay三角网。
上述基于散点的构网算法理论严密、唯一性好,网格满足空圆特性,较为理想。由其逐点插 入的构网过程可知,遇到非Delaunay边时,通过删除调整,可以构造形成新的Delaunay边。在完成构网后,增加新点时,无需对所有的点进行重新 构网,只需对新点的影响三角形范围进行局部联网,且局部联网的方法简单易行。同样,点的删除、移动也可快速动态地进行。但在实际应用当中,这种构网算法当 点集较大时构网速度也较慢,如果点集范围是非凸区域或者存在内环,则会产生非法三角形。
2.2.Bowyer-Watson算法
Lawson算法的基本步骤是:
1、构造一个超级三角形,包含所有散点,放入三角形链表。
2、将点集中的散点依次插入,在三角形链表中找出其外接圆包含插入点的三角形(称为该点的影响三角形),删除影响三角形的公共边,将插入点同影响三角形的全部顶点连接起来,从而完成一个点在Delaunay三角形链表中的插入。
3、根据优化准则对局部新形成的三角形进行优化。将形成的三角形放入Delaunay三角形链表。
4、循环执行上述第2步,直到所有散点插入完毕。
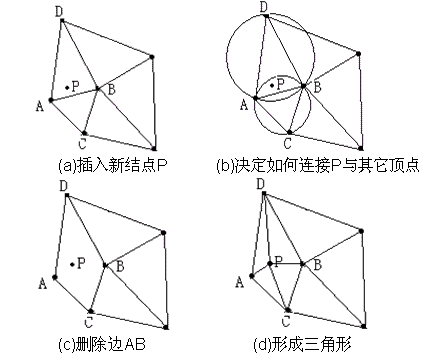
这一算法的关键的第2步图示如下:
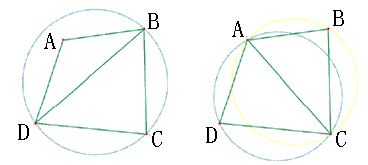
2、最大化最小角特性:在散点集可能形成的三角剖分中,Delaunay三角剖分所形成的三角形的最小角最大。从这个意义上讲,Delaunay 三角网是“最接近于规则化的“的三角网。具体的说是指在两个相邻的三角形构成凸四边形的对角线,在相互交换后,六个内角的最小角不再增大。如下图所示:
1.4.Delaunay三角剖分的特性
以下是Delaunay剖分所具备的优异特性:
本篇文章来自 地模网-打造最专业的建模网站|www.geomodel.net 原文链接:http://www.geomodel.net/article/code/20080601/7510.html
1.Delaunay三角剖分&Voronoi图定义
2.计算Delaunay三角剖分的算法及分析
3.例子程序&代码
大话
点集的三角剖分(Triangulation),对数值分析(比如有限元分析)以及图形学来说,都是极为重要的一项预处理技术。
尤其是Delaunay三角剖分,由于其独特性,关于点集的很多种几何图都和Delaunay三角剖分相关,如Voronoi图,EMST树,Gabriel图等。Delaunay三角剖分有几个很好的特性:
1.最大化最小角,“最接近于规则化的“的三角网。
2.唯一性(任意四点不能共圆)。
概念及定义
二维实数域(二维平面)上的三角剖分
定义1:假设V是二维实数域上的有限点集,边e是由点集中的点作为端点构成的封闭线段, E为e的集合。
那么该点集V的一个三角剖分T=(V,E)是一个平面图G,该平面图满足条件:
1.除了端点,平面图中的边不包含点集中的任何点。
2.没有相交边。
3.平面图中所有的面都是三角面,且所有三角面的合集就是点集V的凸包。
那什么是Delaunay三角剖分呢?不过是一种特殊的三角剖分罢了。从Delaunay边说起。
Delaunay边
定义2:假设E中的一条边e(两个端点为a,b),e若满足下列条件,则称之为Delaunay边:
存在一个圆经过a,b两点,圆内不含点集V中任何的点,这一特性又称空圆特性。
Delaunay三角剖分
定义3:如果点集V的一个三角剖分T只包含Delaunay边,那么该三角剖分称为Delaunay三角剖分。
我们看几个图:
由上面的图引出Delaunay三角剖分的另一种定义:
定义4:假设T为V的任一三角剖分,则T是V的一个Delaunay三角剖分,当前仅当T中的每个三角形的外接圆的内部不包含V中任何的点。
Voronoi图
定义5:V的Voronoi图是由多边形区域的集合(有些区域可能不是闭合的),该区域仅含点集中的一个点v,区域中的任何位置到v的距离都比该位置到点集中其它所有点的距离短。
由Voronoi图和Delaunay三角剖分的关系,可以引出另一个Delaunay三角剖分的定义:
定义6:将Voronoi图相邻区域(共边的区域)中的点连接起来构成的图,称为Delaunay三角剖分。
如下图:
概念部分到此,下面看看怎么求Delaunay三角剖分。
计算Delaunay三角剖分
问题1:计算二维Delaunay三角剖分
问题输入:二维实数域上的点集V
问题输出:Delaunay三角剖分DT = (V, E).
算法
由不同的定义对应有不同的算法。用得较多的是基于定义3或4的算法。
目前常用的算法又分为好几种,被不同的家伙发现。什么扫描线法(Sweepline),随机增量法(Incremental),分治法(Divide and Conquer)啊等等。
随机增量法(Incremental)
其中,随机增量法较为简单,遵循增量法的一贯思路,即按照随机的顺序依次插入点集中的点,在整个过程中都要维护并更新一个与当前点集对应的Delaunay三角剖分。考虑插入vi点的情况,由于前面插入所有的点v1,v2,...,vi-1构成的DT(v1,v2,...,vi-1)已经是Delaunay三角剖分,只需要考虑插入vi点后引起的变化,并作调整使得DT(v1,v2,...,vi-1) U vi成为新的Delaunay三角剖分DT(v1,v2,...,vi)。
(插入调整过程:首先确定vi落在哪个三角形中(或边上),然后将vi与三角形三个顶点连接起来构成三个三角形(或与共边的两个三角形的对顶点连接起来构成四个三角形),由于新生成的边以及原来的边可能不是或不再是Delaunay边,故进行边翻转来调整使之都成为Delaunay边,从而得出DT(v1,v2,...,vi)。)
其Pseudocode如下:
Algorithm IncrementalDelaunay(V)
Input: 由n个点组成的二维点集V
Output: Delaunay三角剖分DT
1.add a appropriate triangle boudingbox to contain V ( such as: we can use triangle abc, a=(0, 3M), b=(-3M,-3M), c=(3M, 0), M=Max({|x1|,|x2|,|x3|,...} U {|y1|,|y2|,|y3|,...}))
2.initialize DT(a,b,c) as triangle abc
3.for i <- 1 to n
do (Insert(DT(a,b,c,v1,v2,...,vi-1), vi))
4.remove the boundingbox and relative triangle which cotains any vertex of triangle abc from DT(a,b,c,v1,v2,...,vn) and return DT(v1,v2,...,vn).
Algorithm Insert(DT(a,b,c,v1,v2,...,vi-1), vi)
1.find the triangle vavbvc which contains vi // FindTriangle()
2.if (vi located at the interior of vavbvc)
3. then add triangle vavbvi, vbvcvi and vcvavi into DT // UpdateDT()
FlipTest(DT, va, vb, vi)
FlipTest(DT, vb, vc, vi)
FlipTest(DT, vc, va, vi)
4.else if (vi located at one edge (E.g. edge vavb) of vavbvc)
5. then add triangle vavivc, vivbvc, vavdvi and vivdvb into DT (here, d is the third vertex of triangle which contains edge vavb) // UpdateDT()
FlipTest(DT, va, vd, vi)
FlipTest(DT, vc, va, vi)
FlipTest(DT, vd, vb, vi)
FlipTest(DT, vb, vc, vi)
6.return DT(a,b,c,v1,v2,...,vi)
Algorithm FlipTest(DT(a,b,c,v1,v2,...,vi), va, vb, vi)
1.find the third vertex (vd) of triangle which contains edge vavb // FindThirdVertex()
2.if(vi is in circumcircle of abd) // InCircle()
3. then remove edge vavb, add new edge vivd into DT // UpdateDT()
FlipTest(DT, va, vd, vi)
FlipTest(DT, vd, vb, vi)
Algorithm InCircle(va, vb, vd, vc)
if |a^b^, c^b^, d^b^| > 0, vd is NOT in the circumcircle of abc //a^坐标为(ax,ay,ax*ax+ay*ay),a^b^为向量
if |a^b^, c^b^, d^b^| == 0, vd is on the circumcircle of abc
if |a^b^, c^b^, d^b^| < 0, vd is in the circumcircle of abc
Note: Details of InCircle():
如下图:
抛物线P (z = x*x + y*y), 现有x-y平面上a,b,c三点,现在要测试点d是否在a,b,c的外接圆内,将a,b,c,d四点lift up,与P相交于a^,b^,c^,d^,则有:
case 1:如果d正好位于外接圆上,则d^必在由a^,b^,c^三点构成的平面H上。此刻向量a^b^, c^b^, d^b^构成的矩阵的行列式det==0
case 2:如果d位于外接圆内,即d',则d'^必在由a^,b^,c^三点构成的平面H下面。即向量a^b^, c^b^, d^b^构成的矩阵的行列式det<0
case 3:如果d位于外接圆外,即d'',则d''^必在由a^,b^,c^三点构成的平面H上面。即向量a^b^, c^b^, d^b^构成的矩阵的行列式det>0
复杂度分析
问题的规模为点集中的点的总个数n(没有重合的点),循环内的基本的操作有:
1.寻找插入点所在的三角形(FindTriangle())
2.测试点是否在外接圆内(InCircle())
3.更新三角网(UpdateDT())
4.寻找共测试边的第三顶点(FindThirdVertex())
考虑最坏情况:
时间复杂度T = T(addboudingbox()) + Sum(T(insert(i), i=1,2,...,n)) + T(removeboundingbox)
因为addboudingbox()和removeboundingbox不随n变化,是个常量。T(addboudingbox()) = O(1), T(removeboundingbox()) = O(1).
T = Sum(T(insert(i), i=1,2,...,n)) + O(1) + O(1).
考虑插入第i个的点的时间:
T(insert(i)) = T(FindTriangle(i)) + T(UpdateDT(i)) + K*T(FlipTest(i)) (K为常数)
故T = Sum(T(FindTriangle(i)), i=1,2,..,n) + Sum(T(UpdateTD(i)), i=1,2,..,n) + K*Sum(T(FlipTest(i)), i=1,2,..,n)
挨个考虑:
FindTriangle(i)是要找出包含第i个点的三角形,由欧拉公式知道,平面图的面数F是O(n), n为顶点数,故此时总的三角形数是O(i)的。所以问题相当于在O(i)个记录中查找目标记录,如果不借助特殊的数据结构,按照一般顺序查找,需要O(i)的时间。
T(FindTriangle(i)) = O(i),故:Sum(T(FindTriangle(i)), i=1,2,..,n) = O(n*n)
UpdateTD(i)是更新三角网数据结构,插入和删除三角形到当前的三角网是个常量操作,因为已经知道插入和删除的位置。
T(UpdateDT(i)) = O(1),故:Sum(T(UpdateTD(i)), i=1,2,..,n) = O(n)
FlipTest(i)比较复杂些,是个递归过程。细分为:T(FlipTest(i)) = T(FindThirdVertex(i)) + T(InCircle(i)) + T(UpdateDT(i)) + 2*T(FlipTest(j))。(这里,用j来区分不同的深度)
因为InCircle(i)是测试点是否在外接圆内,是个常量操作,不随点数变化而变化。故T(InCircle(i)) = O(1), 又T(UpdateDT(i) = O(1)(见上)
FindThirdVertex(i)是查找目标点,在O(i)个记录中查找目标记录,如果不借助特殊的数据结构,按照一般顺序查找需要O(i)的时间。T(FindThirdVertex(i)) = O(i).
剩下的是递归调用FlipTest的过程,不过还好,因为FlipTest的递归深度只有常数级(设为K)。正比于点在三角网中的度数(degree)。故FlipTest(i)最多调用的次数为2*2*,...,2 = K',还是常数。
故T(FlipTest(i)) = O(i) + O(1) + O(1) + K'*(O(i) + O(1) + O(1)) = O(i) + O(1) + O(1) .
Sum(T(FlipTest(i)), i=1,2,..,n) = O(n*n) + O(n) + O(n)
综上,最坏情况下算法总时间复杂度 T = O(n*n) + O(n) + K*(O(n*n) + O(n) + O(n)) + O(1) + O(1) = O(n*n)
其中,关键的操作是FindTriangle()和FindThirdVertex(),都是n*n次的。
在网上很多资料说随机增量法是O(nlogn)的,但是分析下来,却是O(n*n)的。后来看到别人的实现,原来是用的别的数据结构来存储三角网,减少了FindTriangle()和FindThirdVertex()的复杂度。使得某次查找三角形和共边三角形的第三顶点能在O(logn),而非O(n)的时间内实现。这样,总的查找的时间为 O(log1)+O(log2)+,...+O(logn) = O(nlogn)。程序=算法+数据结构,看来一点没错。
比如说用DAG,Quad-edge等,都能达到O(nlogn)的复杂度。
分治法(Divide and Conquer)
据说是现在实际表现最好的。
扫描线法(Sweepline)
有空再看看其算法思路。
例子程序&代码
网上由很多代码关于计算Delaunay的库,如Triangle, Qhull,
https://blog.sciencenet.cn/blog-116465-216935.html
上一篇:希尔伯特23个数学问题及其解决情况(转载)
下一篇:[转载]多核编程的几个难题及其应对策略