博文
卫生统计方法的R软件处理
||
卫生统计方法的R软件处理
扬州职业大学 王晓刚(225000)
摘要:本文介绍了常见卫生统计方法的R软件处理.
关键字:卫生统计学、统计方法、R软件
0.R软件介绍
在现代信息处理技术飞速发展的今天,使用计算机软件处理统计数据,已成为一致的选择.市场上流行的统计软件很多,较为主流的有三种:SAS、SPSS及S-PLUS,它们都是很优秀的统计分析软件,但是都需要付费.而由Aucklang(奥克兰)大学的Robert Gentleman和RossIhaka及其它志愿人员开发、目前一直由R核心开发小组维护的R软件,却是一款完全免费的统计分析软件,用户可以通过R软件的网站(地址是:http://www.r-project.org)了解有关R软件的最新信息和使用说明,得到最新版的R软件和基于R的应用统计软件包.
R具有完整的统计分析、统计制图及数据文件的读写功能,可以在UNIX、Windows或Macintosh操作系统上运行,并自带一个非常实用的帮助系统.说R是一种统计软件,倒不如说R是一种基于S语言的开放的统计编程环境.R不仅提供了若干内嵌的统计函数,用户还可编制自己的R函数来扩展自已的R系统,完成科研工作.
1.R软件常见的数据组织方式
R软件的数据组织方式有多种,限于篇幅原因,这里只介绍三种:向量、矩阵与数据框.
建立向量的命令是c ( ),常用于输入样本数据.如下述命令是将一个样本数据组成的数组输入存储在变量x中.
> x<-c (3, 2, 9,18,8,0,7,5) //大于号是R软件命令提示符
//小于号"<"与减号"-"相当于一个方向箭头,表示对变量的赋值
建立矩阵的常用命令是matrix ( ),用于输入二维表格数据如四格表或行×列表数据.如下述命令是将上述向量x定义成2行4列矩阵,保存在在变量a中,元素按行排列,即第一行的元素是3, 2, 9,18,第二行的元素是8,0,7,5.
>a<-matrix(x,nrow=2,ncol=4,byrow=TRUE) //byrow=TRUE是指示数据按行处理
建立数据框的方法常用的有两种,一种是使用命令read.table ( ).具体示例如下:
例1利用操作系统自带的记事本,建立如下格式所示的文本文件,也可将Excel工作表文件另存为制表符分隔的文本文件,不妨设文件名是“example.txt”.
| Name | Sex | Age | Height | Weight |
| Alice | F | 13 | 56.5 | 84.0 |
| Becka | F | 14 | 64.3 | 90.0 |
| James | M | 14 | 57.3 | 83.0 |
| John | M | 13 | 62.5 | 84.0 |
| Kathy | F | 12 | 59.8 | 84.5 |
然后通过下述命令将文本文件“example.txt”中所含的记录单,读入内存,以数据框的形式存储于变量rt中,其中文件名前可带路径.
>rt<-read.table("example.txt",head=TRUE) //head=TRUE是指示将文件第一行作为列名处理
建立数据框的另一种方法是使用命令data.frame( ).例1中的数据框也可直接这样建立:
>rt<-data.frame(
Name=c("Alice","Becka "," James "," John "," Kathy "),
Sex=c("F","F","M","M","M"),
Age=c(13,14,14,13,12),
Height=c(56.5,64.3, 57.3, 62.5, 59.8),
Weight=c(84.0,90.0,83.0,84.0,84.5)
)
数据写盘命令是write.table( ),如将上述数据框变量rt写盘的命令是
>write.table(rt,file="examplew.txt") //文件名前可带路径
2.定量数据统计描述的R实现
例2假设一个定量资料样本的数据保存在向量x中,对该样本统计描述的R操作如下:
>n<-length(x) //计算样本容量并存放于变量n中
>m<-mean(x) //计算样本均数并存放于变量m中
>v<-var(x) //计算样本方差并存放于变量v中
>s<-sd(x) //计算样本标准差并存放于变量s中
>med<-median(x) //计算样本中位数并存放于变量med中
>cv<-100*s/m //计算样本变异系数并存放于变量cv中
>R<-max(x)-min(x) //计算样本极差并存放于变量R中
>R1<-quantile(x,3/4)-quantile(x,1/4)
//计算样本并存放于变量R1中, quantile是百分位数函数
>sm<-s/sqrt(n) //计算样本标准误并存放于变量sm中
> kurt <-n/((n-1)*(n-2))*sum((x-m)^3)/s^3
//计算样本偏度并存放于变量kurt中
> skew <-((n*(n+1))/((n-1)*(n-2)*(n-3))*sum((x-m)^4)/s^4-(3*(n-1)^2)/((n-2)*(n-3)))
//计算样本峰度并存放于变量skew中
> hist(x,nclass=15) //作出样本数据频数分布直方图并在终端输出
//nclass=15用于指定分组个数,一般实际分组个数比指定个数略大
//大多数情况下该参数可以省略而采用系统默认分组个数
>description=data.frame(N=n,Mean=m,Var=v,Stg_dev=s,Median=med,CV=cv,
R=R,R1=R1,Std_mean=sm,Krut=kurt,Skew=skew)
//汇总结果用于显示输出或存盘
3.正态总体假设检验的R实现
参数检验常见的有正态性检验、正态总体均值的t检验、正态总体方差的卡方检验与F检验等.
3.1 .正态性检验
如果变量x中存储的是某一个样本的定量数据,那么检验该样本是否来自正态总体的常用方法是使用函数shapiro.test( ),具体如下:
>shapiro.test(x)
该命令将在终端输出W统计量及假设检验概率P值,P值小于检验水准(如0.05)那么就拒绝无效假设,认为样本数据不是来自于正态总体,否则接收无效假设,认为样本数据来自于正态总体.
3.2.正态总体均值的t检验
正态总体均值的假设检验命令是t.test( ),具体格式是
t.test(x, y = NULL,alternative =c("two.sided", "less", "greater"),paired = FALSE,
mu = 0, var.equal = FALSE,conf.level = 0.95,...)
其中,参数x与y是样本数据向量,参数alternative以指明是单侧检验还是双侧检验,参数paired用于指定是否配对检验,默认不,参数mu以指定待检验的总体均数,默认是0,参数var.equal以指明方差是否齐,默认是不齐"F",方差齐则指定"T",参数conf.level以指明置信度,默认是0.95.具体有三种情况.
第一,样本均数与总体均数比较的t检验.
例3已知正常男子血小板计数均值为225,今测得20名男性油漆作业工人的血小板资料是(单位:109/L):
220 188 162 230 145 160 238 188 247 113 126 245 164 231 256 183 190 158 224 175
问男性油漆工人的血小板计数与正常成年男子有无差异?该问题的R操作是
> x<-c(220,188,162,230,145,160,238,……,190,158,224,175)
>t.test(x,mu=225,conf.level=0.95)
软件将输出统计量t值,自由度以及假设检验概率值,用于作出统计推断.另外软件还将输出根据样本数据所作出的对总体均数的点估计与区间估计.具体如下:
One Samplet-test
data: x
t = -3.4783,df = 19, p-value = 0.002516 //输出t值、自由度、假设检验概率值
alternativehypothesis: true mean is not equal to 225
95 percentconfidence interval:
172.3827 211.9173 //输出总体均数置信度95%的置信区间
sampleestimates:
mean of x
192.15 //输出总体均数点估计值即样本均数
结果表明,假设检验概率等于0.002516,认为男性油漆工人的血小板计数异于正常成年男子.
第二,配对定量数据的t检验.
例4为研究某铁剂治疗和饮食治疗营养性缺铁性贫血的效果,将16名患者按年龄、体重、病程和病情相近的原则配成8对,分别使用饮食疗法和补充铁剂治疗的方法,3个星期后测得两种患者血红蛋白如下表所示
配对号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
铁剂治疗 | 113 | 120 | 138 | 120 | 100 | 118 | 138 | 123 |
饮食治疗 | 138 | 116 | 125 | 136 | 110 | 132 | 130 | 110 |
问两种方法治疗后的患者血红蛋白有无差异?该问题的R操作是
> x<-c(113,120, 138, 120, 100, 118, 138, 123); y<-c(138, 116, 125, 136, 110, 132, 130,110)
>t.test(x-y) //x-y也可表示配对
软件将输出统计量t值,自由度以及假设检验概率值等与例3类似的信息.
One Sample t-test
data: x - y
t = -0.6513,df = 7, p-value = 0.5357 //输出t值、自由度、假设检验概率值
alternativehypothesis: true mean is not equal to 0
95 percentconfidence interval:
-15.62889 8.87889
sampleestimates:
mean of x
-3.375
结果表明,假设检验概率等于0.5357,不能认为两种方法治疗后的患者血红蛋白有差异.
第三,两样本均数比较的t检验,包括方差齐与方差不齐两种情况,方差齐性检验后面阐述.
例5某克山病区测得11例急性克山病患者与13名健康人的血磷值(mg%)如下
患者:2.60, 3.24, 3.73, 3.73, 4.32, 4.73, 5.18, 5.58, 5.78,6.40, 6.53
健康人:1.67, 1.98, 1.98, 2.33, 2.34, 2.50, 3.60, 3.73, 4.14,4.17, 4.57, 4.82, 5.78
问该地区急性克山病患者与健康人的血磷值是否不同?该问题的R操作是
> x<-c(2.60,3.24,3.73,3.73,4.32,4.73,5.18,5.58,5.78,6.40,6.53)
> y<-c(1.67,1.98,1.98,2.33,2.34,2.50,3.60,3.73,4.14,4.17,4.57,4.82,5.78)
>t.test(x,y,var.equal = T)
软件将输出统计量t值,自由度以及假设检验概率值等与例3类似的信息.
Two Sample t-test
data: x and y
t = 2.5394,df = 22, p-value = 0.01868 //输出t值、自由度、假设检验概率值
alternativehypothesis: true difference in means is not equal to 0
95 percentconfidence interval:
0.2486260 2.4639614
sampleestimates:
mean of xmean of y
4.710909 3.354615
结果表明,假设检验概率等于0.01868,认为该地区急性克山病患者与健康人的血磷值不同.
3.3.正态总体方差的假设检验
正态总体方差的假设检验有两种情况
第一,样本方差与总体方差比较的卡方检验.
例6通常情况下某总体的方差是64,现抽得10个观察单位的数据是578 572 570 568 572 570 572 596 584 570(单位:kg),试问能否认为这10个观察单位是来自于该总体?该问题的R操作是
>x<-c(578,572,570,568,572,570,572,596,584,570)
>n<-length(x); v<-var(x); v0<-64
>chi2<-(n-1)*v/v0 //计算统计量卡方值
> if(pchisq(chi2,n-1)<0.5)P =2*pchisq(chi2,n-1) else P =2*(1-pchisq(chi2,n-1))
//条件选择命令,以从卡方值得到双侧检验概率值
// 命令函数pchisq是卡方分布函数
>data.frame(var=v,df=n-1,chisq2=chi2,P_value=P) //汇总结果用于显示输出或存盘
软件将输出统计量卡方值,自由度以及假设检验概率值.具体如下:
var df chisq2 P_value
175.73333 9 10.65 0.6009287
结果表明,假设检验概率等于0.6009278,可认为这10个观察单位是来自于该总体.
第二,两个样本方差是否齐性的F检验.
例7对例5中两个样本的方差齐性检验如下
> x<-c(2.60,3.24,3.73,3.73,4.32,4.73,5.18,5.58,5.78,6.40,6.53)
> y<-c(1.67,1.98,1.98,2.33,2.34,2.50,3.60,3.73,4.14,4.17,4.57,4.82,5.78)
> vx<-var(x);vy<-var(y) //一个命令行可输入两个命令,中间用分号分隔
> nx<-length(x);ny<-length(y)
> F<-vx/vy //用于计算统计量F值
> if(pf(F,nx-1,ny-1)<0.5)P =2*pf(F,nx-1,ny-1) else P =2*(1-pf(F,nx-1,ny-1))
//条件选择命令,以从F值得到双侧检验概率值
// 命令函数pf是F分布函数
>data.frame(var_of_x=vx, df_x=nx-1,var_of_y=vy,df_y=ny-1,F_value=F, P_value=P)
软件将输出统计量F值,自由度以及假设检验概率值,用于统计推断.具体如下:
| var_of_x | df_x | var_of_y | df_y | F_value | P_value |
| 1.697749 | 10 | 1.701377 | 12 | 0.9978677 | 0.9879321 |
结果表明,假设检验概率等于0.9879321,可认为两个样本的方差齐.
4.二项分布总体的假设检验的R实现
在二项分布总体中,总体概率的区间估计与假设检验的命令函数均是binom.test( ),具体格式如下:
binom.test(x, n, p = 0.5,conf.level = 0.95)
其中x是表现次数,n是观察次数,p是原假设的概率,conf.level是置信度.系统将输出假设检验概率值及根据样本数据所作出的对总体概率的点估计与区间估计.
5.四格表资料或行×列表资料的卡方检验的R实现
四格表资料与行×列表资料的卡方检验的命令是chisq.test( ),使用格式均是
chisq.test(x, correct = TRUE)
其中,x是存在四格表原始数据的2行2列矩阵或者是行×列表原始数据的行×列矩阵,参数correct用于指明是否使用校正的卡方检验,默认做法是校正.系统将输出统计量卡方值、自由度及假设检验概率值.
如果对不符合卡方检验的资料用卡方检验或者应该使用校正的卡方检验时而使用了未校正的卡方检验,那么R软件将在输出结果的同时给出一个警告.
另外,四格表资料的确切概率的计算命令是fisher.test(),使用格式是
fisher.test(x)
6.秩和检验的R实现
秩和检验包括配对样本的秩次和检验与非配对资料的秩次和检验.本文仅介绍在探测差异性方面更为有效的威尔克森秩检验,命令函数是wilcox.test( ).
第一,配对样本的威尔克森秩检验.
例8 12名宇航员航行前及返航后24小时的心率(次/分)如下,问航行对心率有无影响?
序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
航前 | 76 | 71 | 70 | 61 | 80 | 59 | 74 | 62 | 79 | 72 | 84 | 63 |
航后 | 93 | 68 | 65 | 65 | 93 | 78 | 83 | 79 | 98 | 78 | 90 | 60 |
该问题的R操作如下
>x<-c(76, 71, 70, 61, 80, 59, 74, 62, 79, 72, 84, 63);
y<-c(93, 68, 65,65, 93, 78, 83, 79, 98, 78, 90, 60)
>wilcox.test(x-y,,exact=F) //x-y表示配对,exact=F表示不进行精确概率计算
软件输出如下:
Wilcoxon signed rank test withcontinuity correction
data: x - y
V = 7,p-value = 0.01333
alternativehypothesis: true location is not equal to 0
结果表明,假设检验概率等于0.01333,认为宇航员航行前及返航后24小时的心率前后有差异,航行对心率有影响.
第二,非配对样本的威尔克森秩检验.
例9测得7名铅作业工人与10名非铅作业工人的血铅值(微克/100克)如下表,试问两组工人的血铅值有无差别.
非铅作业组 | 5 | 5 | 6 | 7 | 9 | 12 | 13 | 15 | 18 | 21 |
铅作业组 | 17 | 18 | 20 | 25 | 34 | 43 | 44 |
|
|
|
该问题的R操作如下
>x<-c(5, 5, 6, 7, 9, 12, 13, 15, 18, 21); y<-c(17, 18, 20, 25, 34, 43, 44)
>wilcox.test(x,y,exact=F)
软件输出如下:
Wilcoxon rank sum test with continuitycorrection
data: x and y
W = 4.5,p-value = 0.003376
alternativehypothesis: true location shift is not equal to 0
结果表明,假设检验概率等于0.003376,认为两组工人的血铅值有差别.
7.相关与回归分析的R实现
7.1.相关分析的R实现
相关分析的R操作命令是cor.test(),其使用格式是
cor.test(x, y, alternative = c("two.sided", "less", "greater"), method = c("pearson", "kendall", "spearman"), exact = NULL, conf.level = 0.95, ...)
其中,x与y是数据长度相同的向量,参数alternative以指明双侧检验还是单侧检验,默认是双侧检验,参数method以指明相关系数的三种选择:皮尔逊相关系数、肯达相关系数及斯皮尔曼相关系数,默认是皮尔逊相关系数,参数exact以指明是否精确计算概率,参数conf.level以指明置信度.
例11调查10名20岁男青年的身高与前臂长度如下,试作相关分析.
身高(厘米) | 170 | 173 | 160 | 155 | 173 | 188 | 178 | 183 | 180 | 165 |
前臂长(厘米) | 47 | 42 | 44 | 41 | 47 | 50 | 47 | 46 | 49 | 43 |
该问题的R操作如下
> x=c(170,173, 160, 155, 173, 188, 178, 183, 180, 165); y=c(47, 42, 44, 41, 47, 50, 47,46, 49, 43)
>plot(x,y) //作出x与y的散点图初步观察它们的相关性
>cor.test(x,y)
系统将输出x与y散点图,以及根据样本资料所作作的对相关系数的点估计与区间估计,并对相关系数作t检验的t值、自由度及假设检验的概率值.
具体如下:

Pearson's product-moment correlation
data: x and y
t = 3.6998,df = 8, p-value = 0.006044 //相关系数t检验概率值
alternativehypothesis: true correlation is not equal to 0
95 percentconfidence interval:
0.3297718 0.9492521 //相关系数95%的置信区间
sampleestimates:
cor
0.7944451 //样本相关系数
结果显示,样本相关系数是0.7944451,t检验概率值是0.006044,认为20岁男青年身高与前臂长显著相关.
相关性分析要求样本x样本y均服从正态分布,若这一条件不满足,则可进行x与y的秩相关分析.
例12在肝癌病因研究中,某地调查了10个乡的肝癌死亡率(1/10万)与某种食物中的黄曲霉素相对含量(以最高量为10)的数据,试作秩相关分析.
序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
黄曲霉素相对含量 | 0.7 | 1.0 | 1.7 | 3.7 | 4.0 | 5.1 | 5.5 | 5.7 | 5.9 | 10.0 |
肝癌死亡率(1/10万) | 21.5 | 18.9 | 14.4 | 46.5 | 27.3 | 64.6 | 46.3 | 34.2 | 77.6 | 55.1 |
该问题的R操作如下
> x<-c(0.7,1.0, 1.7, 3.7, 4.0, 5.1, 5.5, 5.7, 5.9, 10.0); x_rank<-rank(x) //计算秩次并存储在向量x_rank中
> y<-c(21.5,18.9, 14.4, 46.5, 27.3, 64.6, 46.3, 34.2, 77.6, 55.1); y_rank<-rank(y)
>cor.test(x_rank,y_rank) //对样本x与y的秩统计量作相关分析
系统将输出秩相关系数的点估计与区间估计,并对秩相关系数作t检验的t值、自由度及假设检验的概率值.具体如下:
Pearson's product-moment correlation
data: x_rank and y_rank
t = 3.1632,df = 8, p-value = 0.01333
alternativehypothesis: true correlation is not equal to 0
95 percentconfidence interval:
0.2182794 0.9358380
sampleestimates:
cor
0.7454545
结果显示,样本相关系数是0.7944451,t检验概率值是0.006044,认为食物中黄曲霉素的含量与肝癌死亡率显著相关.
7.2.回归分析的R实现
回归分析的R命令是lm(),该命令功能很强,不仅可进行线性回归,还可进行非线性回分析,因而命令格式也较复杂,本文仅举例作一元线性回归分析及多元线性回归分析.
例13(一元线性回归分析)在例11中,以身高为自变量,以前臂为因变量作回归分析,R操作如下
> x=c(170,173, 160, 155, 173, 188, 178, 183, 180, 165); y=c(47, 42, 44, 41, 47, 50, 47,46, 49, 43)
>lm.sol<-lm(y~1+x) //将回归分析的结果存储到变量lm.sol中
//函数lm的参数"y~1+x"以指明自变量与因变量及回归方程的形式
>summary(lm.sol) //将回分析的主要结果提取到显示终端
系统将显示回归方程的类型"y~1+x",残差的分布,回归系数据及其标准差、t检验的t值及假设检验概率值,最后是对回归方程作方差分析的F值及假设检验概率值.具体如下:
Call:
lm(formula =y ~ 1 + x)
Residuals:
Min 1Q Median 3Q Max
-3.7148 -0.8039 0.4891 1.2814 1.9740
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.99221 10.72265 0.559 0.59157
x 0.22961 0.06206 3.700 0.00604 **
---
Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05‘.’ 0.1 ‘ ’ 1
Residualstandard error: 1.925 on 8 degrees of freedom
MultipleR-Squared: 0.6311, AdjustedR-squared: 0.585
F-statistic:13.69 on 1 and 8 DF, p-value: 0.006044
结果显示,回归系数是0.22961,t检验概率值是0.00604,具有显著性统计意义,但常数项是10.72265,t检验概率值是0.59157,不具有显著性意义.
例14(多元线性回归分析)对下表数据作线性回归分析.
序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
X1 | 76.0 | 91.5 | 85.5 | 82.5 | 79.0 | 80.5 | 74.5 | 79.0 | 85.0 | 76.5 | 82.0 | 95.0 | 92.5 |
X2 | 50 | 20 | 20 | 30 | 30 | 50 | 60 | 50 | 40 | 55 | 40 | 40 | 20 |
Y | 120 | 141 | 124 | 126 | 117 | 125 | 123 | 125 | 132 | 123 | 132 | 155 | 147 |
该问题的R操作如下
>x1=c(76.0, 91.5, 85.5, 82.5, 79.0, 80.5, 74.5, 79.0, 85.0, 76.5, 82.0, 95.0,92.5)
> x2=c(50,20, 20, 30, 30, 50, 60, 50, 40, 55, 40, 40, 20)
> y=c(120,141, 124, 126, 117, 125, 123, 125, 132, 123, 132, 155, 147)
>lm.sol<-lm(y~1+x1+x2);summary(lm.sol)
系统输出与一元线性回归分析类似.具体如下:
Call:
lm(formula =y ~ 1 + x1 + x2)
Residuals:
Min 1Q Median 3Q Max
-4.0404 -1.0183 0.4640 0.6908 4.3274
Coefficients:
Estimate Std. Error tvalue Pr(>|t|)
(Intercept) -62.96336 16.99976 -3.704 0.004083 **
x1 2.13656 0.17534 12.185 2.53e-07 ***
x2 0.40022 0.08321 4.810 0.000713 ***
---
Signif.codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05‘.’ 0.1 ‘ ’ 1
Residualstandard error: 2.854 on 10 degrees of freedom
MultipleR-Squared: 0.9461, AdjustedR-squared: 0.9354
F-statistic:87.84 on 2 and 10 DF, p-value: 4.531e-07
结果显示,回归方程是
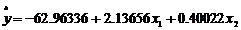
回归参数t检验值分别是0.004083、0.000000253、0.000713,回归方程F检验检验概率是0.0000004531,均具有显著性统计意义.
R软件还具有较强的方差分析、判别分析、聚类分析、主成分分析、因子分析及典型相关分析等功能,因篇幅所限,本文不再赘述.
参考文献:
(1)杨树勤.卫生统计学[M].北京:人民卫生出版社(1978年版).
(2)薛 毅,陈立萍.统计建模与R软件[M].北京:清华大学出版社(2007年版).
此文维普期刊可查。
https://blog.sciencenet.cn/blog-113916-1013095.html
上一篇:新常态下扬州市地方经济发展状况与影响因素分析
下一篇:学生评教数据的统计处理