博文
第三届全国社会媒体处理大会
|
第三届全国社会媒体处理大会于2014年11月在北京召开.
特邀报告
特邀报告1:Big Data Analytics in Business Environments
特邀报告1为美国罗格斯-新泽西州立大学教授熊辉博士所作。
报告一主要介绍了商业环境下的数据挖掘分析。由于大数据自身的特性:巨大,细粒度,多样化,动态等,对于传统的数据挖掘方法都产生了巨大的改变和挑战。该报告着重分析了商业环境中的大数据分析技术和挑战,包括:(1)不同的商业应用的数据挖掘问题;(2)商业分析的数据预处理和后处理问题;(3)如何将计算模型用于管理不确定情况。
特邀报告2:腾讯海量文本挖掘研究与实践
特邀报告2为腾讯工程与技术事业群搜索技术副总监王迪所作。
报告二主要介绍了腾讯研发的文本挖掘平台,包括自然语言处理平台(分词、新词、命名实体识别、同义词、纠错、并行化聚类/分类等)、知识挖掘平台、页面下载和抽取平台、舆情分析和预测平台,以及如何利用这些平台进行现今海量数据的自动挖掘,并且将挖掘结果应用于腾讯的多款产品。其中,以基于用户画像的语义标签搜索和基于社交关系的个性化新闻推荐为例,介绍文本挖掘平台如何在面向社交的语义搜索和推荐场景中发挥作用。
特邀报告3:Social Information Filtering – A Case Study on Weibo
特邀报告3为华为技术有限公司诺亚方舟实验室首席科学家李航所作。
报告三介绍了如何进行社交信息过滤。最终目的是为用户构建信息助手从而有助于用户简单快速地获取信息。他们利用社交媒体来构建信息助手,并将之称为“社会信息过滤”。他们着重利用微博机器人——小诺的发展来进行社会信息过滤的实验。
特邀报告4:大数据机会与风险——谈与人行为相关的大数据分析
特邀报告4为北京大学传播学系教授刘德寰所作。
报告四主要介绍了大数据的理念误区,大数据的分析层次,大数据中的机会以及大数据中的伦理。他认为大数据中的三个危险观念为:对抽样的蔑视,无原则推崇相关以及全数据。大数据的到来引起了众多方法论的问题,并以google为例说明大数据的弊端。
特邀报告5:大数据改变世界
特邀报告5为北京拓尔思信息技术股份有限公司高级副总裁林春雨所作。
报告五主要介绍了大数据技术对各行各业的冲击和变化,大数据可以改进政府的决策,反馈真实民意,优化管理水平。大数据可以助力优化企业的口碑管理,维护企业,改进服务流程,大数据正在成为目前所有行业的驱动力。
特邀报告6:海量基于社会媒体的行业大数据实践
特邀报告6为海量信息技术有限公司创始人董事长郝玺龙所作。
报告六主要介绍了如何将社会媒体信息转化为可以指导行动的情报。大数据具备数据规模大、数据多样性、数据在运动中及数据不确定性的特点,从纷繁复杂的海量数据进行收集整理后经过挖掘获得对组织和个人的决策形成支撑的知识或情报,对技术支撑平台的数据全面性、时效性和准确性提出了更高的要求。该报告介绍了“海量”基于十余年的中文智能计算和互联网数据挖掘技术的积累而打造的大数据技术体系,并将以大数据在娱乐行业的应用(爸爸去哪儿第二季)为例,展示海量在大数据时代为行业提供情报服务的独特竞争力。
特邀报告7:社会信号的解析与应用-从CMO到智慧管理
特邀报告7为中国科学院自动化研究所复杂系统管理与控制国家重点实验室主任王飞跃教授所作。
报告七主要介绍了闭环反馈自适应式的实时开放式社会管理与服务是否可能?能否成就一个崭新的社会自动化时代?该报告认为,社会信号的有效解析(Analytics)和知识自动化将是实理这一目标的核心与关键,而研究并掌握各类CyberMovement Organizations (CMOs)的形态与发展更是实现智能企业和智慧社会管理的必经之路。


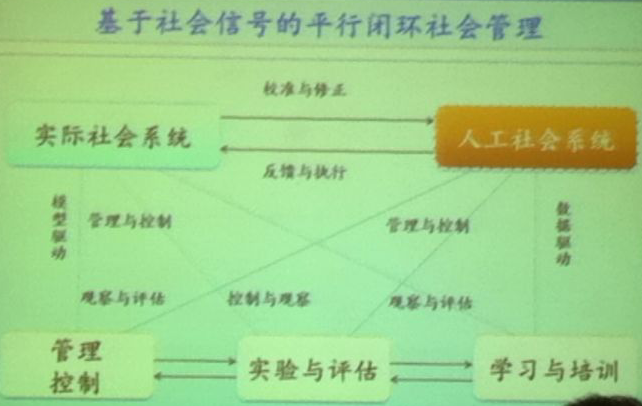

特邀报告8:Mining Social Media: Look Ahead
特邀报告8为美国亚利桑那州立大学刘欢教授所作。
报告八主要介绍了社会媒体挖掘。社会媒体为我们提供了沟通与交流,也为研究人员了解人们创新的透镜的一种新方法。社会媒体挖掘是在规模化处理社会媒体的一种有效途径。我们目前面临的问题有:(1)大数据悖论,(2)信任VS不信任社会媒体,(3)数据样本的可信度问题,以及(4)评价困境。这些挑战使得我们有机会了解社会媒体的数据及其特性,从而进行跨学科的研究与发现。


特邀报告9:在线社交网络分析—理论与实践
特邀报告9为国防科学技术大学教授贾焰教授所作。
在线社交网络的出现和飞速发展,深深的影响了大家的学习、工作和生活模式,已成为一个公认的研究热点。社交网络分析在在掌握舆情、突发事件发现、网络营销等方面具有重要作用。本报告首先给出在线社交网络的基本概念和分类。然后,从在线社交网络的三个维度(结构、群体和信息),分析了在线社交网络的数据特点。进一步,给出了在线社交网络分析面临的挑战及问题,并对973课题组团队在线社交网络分析方面的研究进展进行简要介绍。最后,给出了对社交网络研究问题的思考,对在线社交网络下一步的研究方向进行了探索。通过本介绍,可以了解在线社交网络的基本概念、特点和最新研究进展。
特邀报告10:社会媒体环境下在线管理反馈对消费者行为的影响研究
特邀报告10为哈尔滨工业大学管理学院副院长叶强教授所作。
社会媒体环境下,在线客户评论对消费者行为和企业绩效产生着显著的影响。本研究在这一背景下,探索企业针对在线用户评论的应对机制——管理反馈,对企业绩效和消费者满意度的影响。该报告介绍了如何应对负面评价,提出用反馈取代删除的做法。该研究利用携程网酒店客户评论数据,利用假设检验和满意度调查的方法进行管理视角的实证研究,发现了管理反馈对用户行为和用户满意度产生影响的一些基本规律,即管理反馈是有效的处理方法。
特邀报告11:基于社交媒体的用户理解与智能服务
特邀报告11为西北工业大学计算机学院教授於志文所作。
近年来社交媒体迅猛发展,已成为人们日常生活的组成部分,社交网络成为真正的全球现象。用户使用社交媒体产生的数据形成数字足迹,这些足迹反映用户和群体的在物理世界行为,如位置、时间、关系、偏好、情绪等,通过提取用户行为特征和行为规律,能够提供各种智能服务。报告中将介绍移动社交媒体、数字足迹等相关概念,以及研究开发的智能服务。


特邀报告12:社交江湖与媒体数据
特邀报告12为清华大学新闻与传播学院教授沈阳所作。



分会场报告
1、 InferringCorrespondences from Multiple Sources for Microblog User Tags
一些微博服务鼓励用户标注多个标签以说明他们的属性和利益。用户标签对个性化推荐和信息检索发挥重要作用。为了更好的理解用户标签的语义,我们提出了标签的通信模型(TCM)从微博用户丰富的内容识别标签的复杂对应关系。在TCM,我们将一个微博用户的内容分为各种来源。对于有标签的用户,TCM能够自动学习多来源的用户标签。利用学习到的关系,我们能够接受现在的标签语义。此外,对于那些没有任何标签的用户,TCM能够根据用户的内同信息推荐标签。该论文用真实数据进行实验,并证明了该方法的有效确定标签关系,最终可能表示标签的语义信息。
2、 MiningIntention-Related Products on Online Q&A Community
由于社会媒体上的用户生成内容包含了大量的潜在商业机会,所以它已经吸引了大量来自服务和产品供应商的注意。然而,以往的工作主要集中在用户的消费意愿(CI)的识别,少有关于挖掘产品相关意图的研究。在本文中,我们提出了一个新的挖掘意图相关产品的在线问答(Q&A)社区的方法。利用问题-答案对作为数据源,我们首先基于依存句法分析自动提取候选产品。然后通过的搭配抽取模型,,我们从候选产品中确定真实意图相关产品。在我们的精心构建的评估数据上的实验结果表明,我们的方法比两个自然基准方法实现了更好的性能。我们的方法能够进行领域适应。
3、情感词扩展对微博分类性能的影响
在中文微博数据集上分析了基于分类的情感词扩展对微博主观性分类和倾向性分类的影响,从而考察中文微博情感词扩展的必要性,为相关研究工作提供参照或证据。发现采用Naïve 的方法做中文微博“主观性”分类有很大局限性,用它评测情感词扩展方法的好坏要谨慎;采用Naïve 方法做中文微博情感“倾向性”分类时,考虑情感词的情感强度比只统计情感词的个数效果要好,而本文所设计的三种情感强度计算方法性能相当。另外,对于中文微博倾向性分类任务,扩展新情感词时有必要考虑名词类的情感词。
4、情感词发现与极性权重自动计算法研究
随着互联网电子商务和各种社交网络应用的快速发展,产生了大量的用户评价信息。为满足快速整理这些评价信息的需求,情感倾向性分析应运而生。情感词典是各类情感倾向性识别算法的基础,收集一部全面且权重合理的情感词典,往往可以简单快速而有效地解决情感分析问题。但情感词典规模有限,而网络上新的情感词层出不穷,语言使用不规范,人工整理耗时耗力。已有的情感词收集方法较复杂,且领域性强,收集的情感词可扩展性差。本文提出一种自动挖掘潜在情感词并计算其情极性重的算法,该算法与应用领域无关,具有良好的扩展性。该方法利用共现特型,基于朴素贝叶斯公式能检测出未知的情感词,并根据其情感权重值的大小判断其情感极性,可有效地扩展情感词典,将已有的情感词典进一步量化。在理论研究的基础上,本文分别针对京东商城、豆瓣及大众点评网三组评论语料做了实验,其结果的准确率都基本在90%以上,验证了该方法的有效性和实用性,为情感倾向性分析提供了知识库基础。
https://blog.sciencenet.cn/blog-1086141-841887.html
上一篇:第十三届全国计算语言学学术会议(CCL2014)心得记录
全部作者的其他最新博文
全部精选博文导读
相关博文
- • Relativity of Hallucination(初学者版)
- • Are Human Beings Living in a Hallucination?(初学者版)
- • Theory of Relativity of Hallucination by Yucong Duan(初学者版)
- • The "Emergence" of LLMs by Relativity of Consciousness(初学者版)
- • Does Consciousness Depend on Hallucination?(初学者版)
- • Relativity of Consciousness (初学者版)