博文
武汉理工雷德明团队 | 基于强化学习混合蛙跳算法的分布式装配混合流水车间调度  精选
精选
||
2024年初,International Journal of Production Research公布了《2023年度IJPR热门文章列表》,来自中国学者的研究论文占比接近一半。本文将为您介绍入榜文章A novel shuffled frog-leaping algorithm with reinforcement learning for distributed assembly hybrid flow shop scheduling。
分布式装配混合流水车间调度问题(DAHFSP)是混合流水车间调度问题在分布式生产环境下的扩展,是分布式制造和装配的集成,它突破了混合流水车间的单工厂特性,广泛存在于实际工业过程中。DAHFSP具有子问题众多且相互耦合的特点,求解难度非常大,迫切需要新的调度理论方法处理该问题。A novel shuffled frog-leaping algorithm with reinforcement learning for distributed assembly hybrid flow shop scheduling将强化学习嵌入到蛙跳算法的模因组搜索过程中,提出了一种基于强化学习的蛙跳算法(QSFLA),该算法可以获得高质量的调度方案。

DOI:10.1080/00207543.2022.2031331
通讯作者:

雷德明 武汉理工大学
主要研究方向:智能系统优化与控制;数据和知识驱动的优化与控制;人工智能与智能制造;智能工业控制技术
研究介绍
1 分布式装配混合流水车间调度问题
问题定义:DAHFSP描述如下:存在p个产品,Ψh 是部件h=1,2,…,p 的集合。![]() 表示所有产品的部件总数。假设部件1,2,...,|Ψ1|属于产品1,对于h>1 ,产品h的组件记为|Ψh-1| +1,...,|Ψh-1|+ |Ψh|。存在 F个同构工厂,每个工厂为一个装配混合流水车间,每个工厂包含加工、运输和装配三个过程。存在S个加工阶段,第l个加工阶段由ml台同速并行机组成。工厂f第l个加工阶段的第k台机器为Mflk。每个工厂f包含一台运输机器TMf 和一台装配机器AMf 。部件首先分配到工厂f完成加工,当属于同一工件的部件全部加工完成后,这些部件由运输机TMf 收集并运送到装配机AMf处装配。
表示所有产品的部件总数。假设部件1,2,...,|Ψ1|属于产品1,对于h>1 ,产品h的组件记为|Ψh-1| +1,...,|Ψh-1|+ |Ψh|。存在 F个同构工厂,每个工厂为一个装配混合流水车间,每个工厂包含加工、运输和装配三个过程。存在S个加工阶段,第l个加工阶段由ml台同速并行机组成。工厂f第l个加工阶段的第k台机器为Mflk。每个工厂f包含一台运输机器TMf 和一台装配机器AMf 。部件首先分配到工厂f完成加工,当属于同一工件的部件全部加工完成后,这些部件由运输机TMf 收集并运送到装配机AMf处装配。
约束条件:加工机器在同一时刻只能加工一个部件,运输机器和装配机器同一时刻只能运输和装配一个工件;部件在同一时刻只能在一台机器加工,属于同一工件的部件同一时刻只能在一台机器上运输或装配;加工、运输或装配不能中断;所有机器在任意时刻都可用。
问题特点:DAHFSP由工厂分配、机器分配和调度三个子问题组成。三个子问题之间存在强耦合关系。另外,调度子问题还包含工件调度和部件调度。工件调度决定工件的加工顺序,部件调度确定部件的加工顺序。
优化目标:在满足所有约束的条件下最小化最大完成时间。
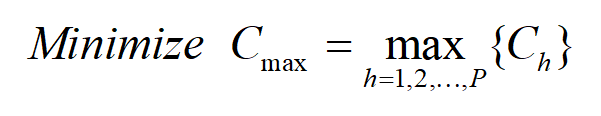
其中Ch表示产品h的完成时间,Cmax 指所有产品的最大完成时间。
2 基于Q学习的蛙跳算法
本研究中将Q学习嵌入到蛙跳算法中,其中状态st由群体的评估值确定,动作at是由全局搜索、邻域搜索和解的接受准则共同确定,动态调整搜索策略。这是将Q-学习与SFLA集成的一种新方法。
采用三串编码方式表达一个解。解码过程如下:
(1) 根据工厂分配串将工件分配到各个工厂,由工件排列和部件排列确定每个工厂中工件和部件的排列;
(2) 根据工件和部件的排列,依次执行加工、运输和装配。当部件在第l个阶段加工时,选择ml台并行机中可利用时间最小的机器。
Q-学习主要包括状态st、动作at、回报rt和动作选择策略。为了实现Q-学习过程,环境状态由种群评估结果确定,根据全局搜索、邻域搜索和解的接受准则设计动作,并重新定义回报的计算方式。由于利用贪婪方式更新xg,种群Pop的xg不会变差,只存在Im=0和Im=1两种情况,由两个指标的组合存在6种状态。动作at由全局搜索、邻域搜索和解的接收准则组成。动作选择采用ε-greedy选择策略。
本研究提供了一种将Q学习和蛙跳算法集成的有效途径。在QSFLA中,通过全局搜索、邻域搜索和解的接受规则定义了四个动作,Q学习用于动态选择一个动作或搜索策略进行模因组搜索。在搜索过程中应用了四种搜索策略,每一代都会动态决定使用的搜索策略,因此,可以有效加强探索能力并显著减少陷入局部最优的可能性。
3 仿真实验
所有实验利用Microsoft Visula C++ 2019编程实现并在8.0G RAM 2.4GHz CPU PC运行。在112个实例上进行了大量的实验,以测试QSFLA对DAHFSP的性能。选择四种算法作为比较算法,包括竞争模因算法、混合粒子群优化算法、混合变量邻域搜索和改进的离散布谷鸟优化算法。利用田口方法确定所有算法的参数。通过实验可以发现QSFLA可以获得比对比算法更好的结果,统计结果如图1所示。

图1 六个算法计算结果的箱线图
QSFLA的良好性能主要源于其Q学习过程。模因组搜索过程中使用了四种搜索策略,并通过Q学习动态调整,因此,探索能力得到了加强;此外,每种策略都由全局搜索和邻域搜索组成,探索和开发能够很好地平衡。因此,QSFLA是解决DAHFSP的非常有竞争力的方法。
4 实际案例
以某一家具公司为例,该公司生产各种家具产品,如不同类型的横向媒体存储柜。每个柜子在所有组件加工完毕并运输到装配车间后,由一些组件组装而成。每个组件的制造过程包括冲压阶段、弯曲阶段、焊接阶段、压力机阶段和钻孔阶段。图2展示了由QSFLA获得Cmax=1120的调度结果。

图2 真实案例的调度甘特图
点击了解International Journal of Production Research期刊

https://blog.sciencenet.cn/blog-3574014-1433836.html
上一篇:图书出版小课堂 | 第二课:图书出版前常见问题FAQ
下一篇:工程与技术开放获取图书 | 从波浪能到建筑安全的技术革新