博文
语音采集中的篱笆墙
|
该研究工作已在Journal of Information and Intelligence在线发表, Li Luo, Yining Liu. Voice Fence Wall: User-Optional Voice Privacy Transmission,Journal of Information and Intelligence. https://doi.org/10.1016/j.jiixd.2023.12.002

随着物联网传感器的广泛应用,越来越多的数据被采集,从而带来了一系列的隐私问题。然而大多研究工作都集中于保护数值、图像和视频数据,却往往忽视了智能语音设备(如:智能音箱、手机麦克风等)为了提供用户诸多服务,从而会随时采集用户的语音数据。其中语音数据包含许多敏感的属性,如情感,身份和性别。如果传感器将收集的原始语音数据传输到上游服务器,服务器可以通过声纹识别,语音情感识别,语音健康检测等技术获取用户大量的敏感属性。因此,需要在语音数据采集之后,即对相关的敏感属性进行隐私化处理,然后上传到服务器(现实中大多不是完全可信的)。
以往的语音隐私保护方法大多通过传统机器学习的方式提取特征,并对语音特征进行加密后上传至上游服务器,这样可以防止其他非授权者获得语音特征,但是上游服务器仍可以根据得到的加密语音特征,通过属性推理的方式来获取语音中包含的敏感属性信息。

图1 Voice Fence Wall 框架图
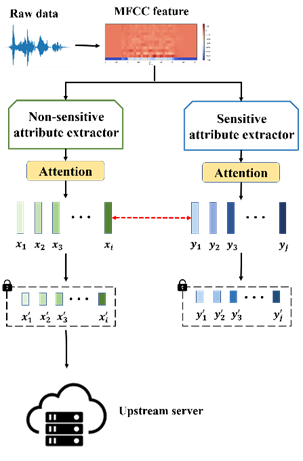
图2 本文提出的特征分离器架构图
为了解决以上问题。需要在设备采集端将语音数据的敏感属性与非敏感属性进行分离,然而传输加密后的非敏感属性,从而保护用户的语音数据。于是本文设计了基于用户选择的语音数据隐私传输框架(称为Voice Fence Wall,语音篱笆墙),如图1所示。为了在Voice Fence Wall框架中实现分离功能,提出了一种特征分离算法,如图2所示,通过计算每个特征提取器中间表示之间的互信息值来优化特征提取器,减少敏感属性与非敏感属性特征之间的相关性,从而实现特征分离。
首先,用户可以选择想要保护的属性(敏感属性);其次,Voice Fence Wall利用最小互信息(MI)降低了敏感属性和非敏感属性之间的相关性,从而实现属性的分离;最后,只将分离的非敏感属性传输到服务器,在不泄漏敏感属性的情况下满足语音服务的质量。
本文的方案在实验上,对比了目前的state of the art(SOTA)如表1。并在三个实际数据集的评估表明,该模块在保护用户隐私信息方面取得了良好的效果。同时也证明了在加入互信息损失和多头注意力机制的情况下,不仅使得模型实现了分离特征的效果,同时也能提高模型的专注度,从而提高了最终服务器的分类准确性。
表1 SOTA方案隐私性与效用性对比

https://blog.sciencenet.cn/blog-3464286-1419572.html
上一篇:大一新生认知提升的重要性远超知识学习
下一篇:初五开工,龙年第一篇论文"面向联邦学习的可验证链式聚合"